豆包视觉理解模型 – 豆包推出视觉理解模型,具备识别和推理能力
2025-01-08 16:49:38 小编:六六导航站
豆包视觉理解模型是什么
豆包视觉理解模型是豆包推出的先进AI大模型,具备视觉识别和理解推理能力。豆包视觉理解模型能识别图像中物体的类别、形状、纹理等,还能理解物体间的关系和场景含义,进行复杂的逻辑计算任务,如解析学术论文图表、诊断代码问题等。模型能细腻地描述视觉内容,创作故事,适用于图片问答、医疗健康、教育科研等多个领域。豆包模型的发布,让视觉理解技术迈入更低成本、更广泛应用时代。

豆包视觉理解模型的主要功能
内容识别能力:识别图像中的物体类别、形状、纹理等基本要素,并理解物体之间的关系、空间布局及场景的整体含义。理解推理能力:模型能识别图文信息,还能进行复杂的逻辑计算,如解微积分题、分析论文图表、诊断真实代码问题等。视觉描述能力:模型具有细腻的视觉描述和创作能力,能基于产品的造型或寓意撰写祝福语,或根据小孩的涂鸦创作奇幻故事。成本优势:豆包视觉理解模型在千tokens输入价格仅为3厘,即0.003元/千Tokens,每处理一张720P的图片成本不到4分钱,相较于行业平均水平,价格降低85%。如何使用豆包视觉理解模型
访问官方网站:访问豆包的官方网站。或访问火山引擎API接口。登录账户:按照提示完成登录和注册。上传图片:根据上传想要模型分析的图片。输入相关文本:输入与图片相关的问题或描述,帮助模型更好地理解图片内容。发起请求:点击提交或发送按钮,对豆包视觉理解模型的发送请求。查看结果:模型处理完毕后,查看返回的结果。豆包视觉理解模型的实测效果
内容识别能力
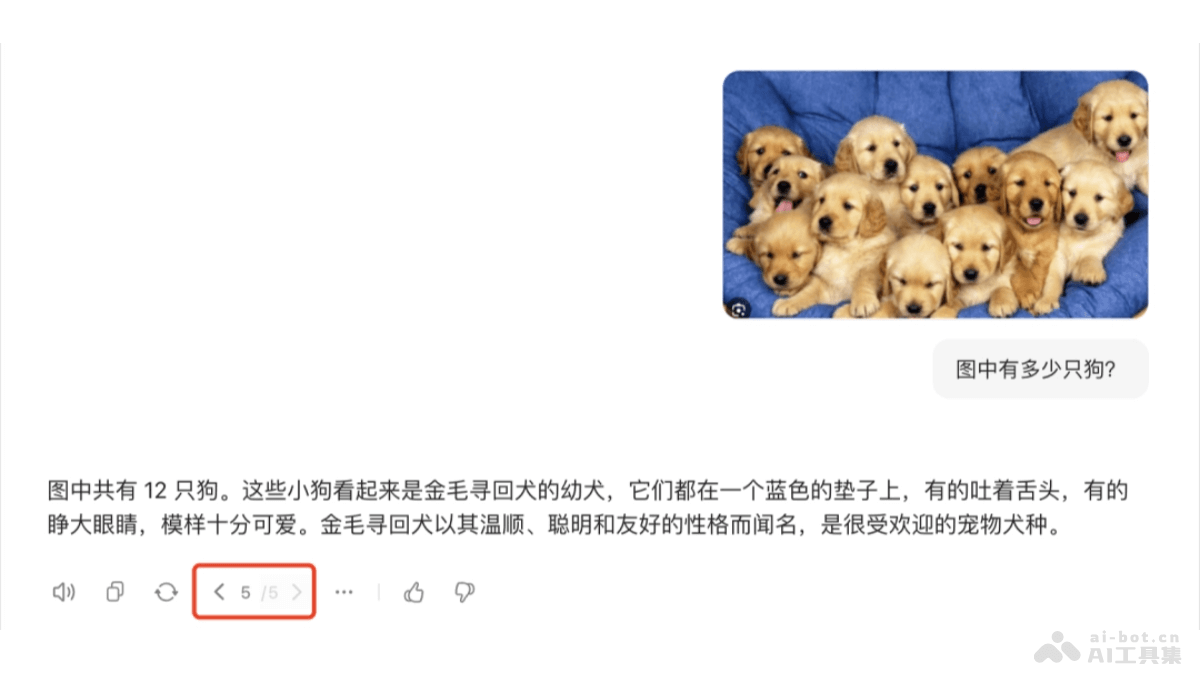 理解推理能力
理解推理能力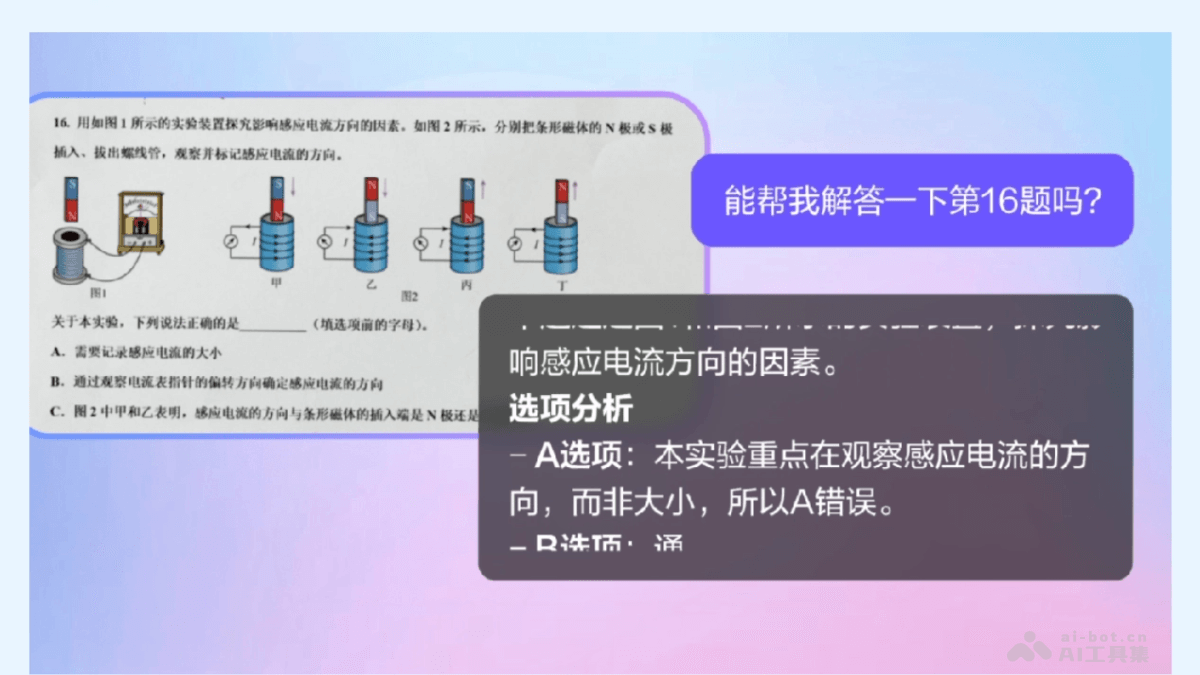
豆包视觉理解模型的应用场景
图片问答(QA):用户上传图片并提出相关问题,模型根据图片内容给出答案。医疗影像分析:在医疗领域,模型帮助分析X光片、CT扫描、MRI等医学影像,辅助医生进行诊断。教育和科研:教育工作者和研究人员分析图表、图解和实验数据,辅助教学和研究。电商和零售:在电商平台,用于商品图片的描述生成、推荐系统和客户服务。内容审核:用于自动审核图片内容,识别和过滤不适宜的内容。- 猜你喜欢
-
 词魂提示指令
词魂提示指令 -
 ChatGPT Shortcut提示指令
ChatGPT Shortcut提示指令 -
 Learning Prompt提示指令
Learning Prompt提示指令 -

-
 PromptVine提示指令
PromptVine提示指令 -

-

-
 MJ Prompt Tool提示指令
MJ Prompt Tool提示指令 -
 绘AI提示指令
绘AI提示指令









- 相关AI应用
-
 AIPRM提示指令
AIPRM提示指令 -
 Snack Prompt提示指令
Snack Prompt提示指令 -
 PublicPrompts提示指令
PublicPrompts提示指令 -
 Generrated提示指令
Generrated提示指令 -
 LangGPT提示指令
LangGPT提示指令 -
 AI Short提示指令
AI Short提示指令 -

-
 ClickPrompt提示指令
ClickPrompt提示指令 -
 PromptHero提示指令
PromptHero提示指令









- 推荐AI教程资讯
- Perplexideez – 开源本地AI搜索助手,智能搜索信息来源追溯
- Micro LLAMA – 教学版 LLAMA 3模型实现,用于学习大模型的核心原理
- GenCast – 谷歌DeepMind推出的AI气象预测模型
- FullStack Bench – 字节豆包联合M-A-P社区开源的全新代码评估基准
- Motion Prompting – 谷歌联合密歇根和布朗大学推出的运动轨迹控制视频生成模型
- Fish Speech 1.5 – Fish Audio 推出的语音合成模型,支持13种语言
- ClearerVoice-Studio – 阿里通义实验室开源的语音处理框架
- PaliGemma 2 – 谷歌DeepMind推出的全新视觉语言模型
- Optimus-1 – 哈工大联合鹏城实验室推出的智能体框架
- Fox-1 – TensorOpera 开源的小语言模型系列


- 推荐阅读阅读排行
-
-





