X-Dyna – 字节联合斯坦福等高校推出的动画生成框架
2025-03-27 15:45:06 小编:六六导航站
X-Dyna是什么
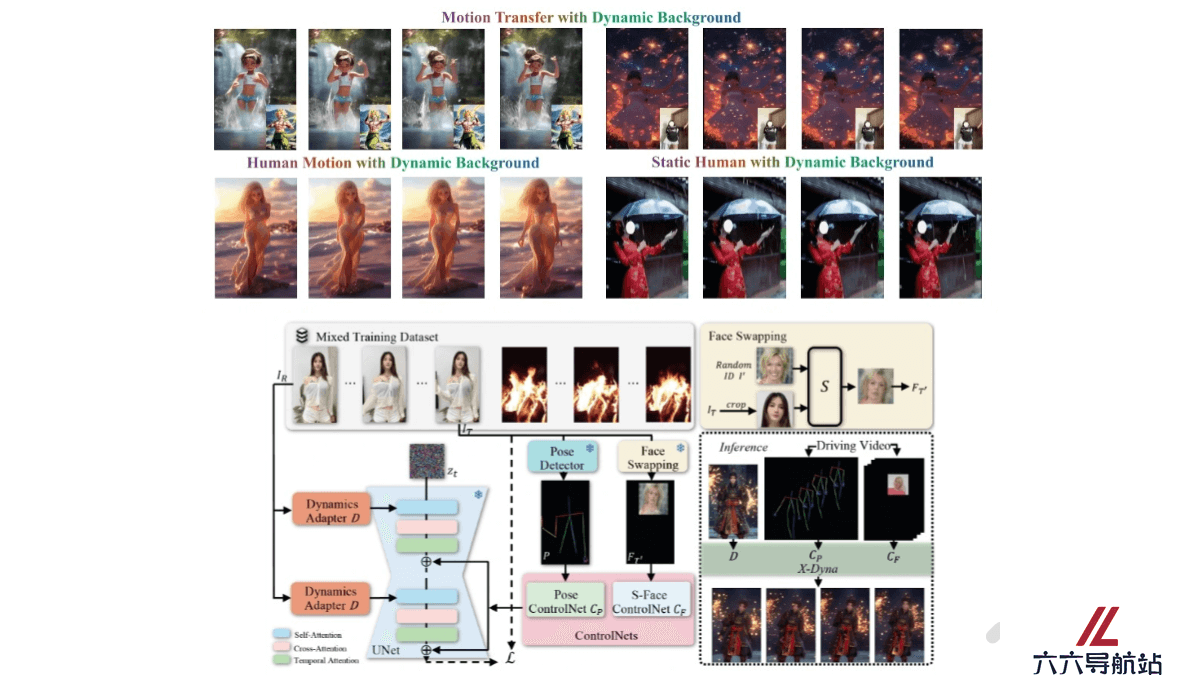
X-Dyna 是基于扩散模型的动画生成框架,基于驱动视频中的面部表情和身体动作,将单张人类图像动画化,生成具有真实感和环境感知能力的动态效果。核心是 Dynamics-Adapter 模块,能将参考图像的外观信息有效地整合到扩散模型的空间注意力中,同时保留运动模块生成流畅和复杂动态细节的能力。
X-Dyna的主要功能
单张图像动画化:X-Dyna 能将单张人类图像通过面部表情和身体动作的驱动,生成具有真实感和环境感知能力的动态视频。面部表情和身体动作控制:工具通过 Dynamics-Adapter 模块,将参考图像的外观信息整合到扩散模型中,同时保留运动模块的动态细节生成能力。还支持面部表情的身份解耦控制,能实现准确的表情转移。混合数据训练:X-Dyna 在人类动作视频和自然场景视频的混合数据集上进行训练,能同时学习人类动作和环境动态。高质量动态细节生成:通过轻量级的 Dynamics-Adapter 模块,X-Dyna 可以生成流畅且复杂的动态细节,适用于多种场景和人物动作。零样本生成能力:X-Dyna 不依赖于目标人物的额外数据,可以直接从单张图像生成动画,无需额外的训练或数据输入。X-Dyna的技术原理
扩散模型基础:X-Dyna 基于扩散模型(Diffusion Model),通过逐步去除噪声来生成图像或视频。Dynamics-Adapter 模块:X-Dyna 的核心是 Dynamics-Adapter,轻量级模块,用于将参考图像的外观信息整合到扩散模型的空间注意力中。具体机制如下:参考图像整合:Dynamics-Adapter 将去噪后的参考图像与带噪声的序列并行输入到模型中,通过可训练的查询投影器和零初始化的输出投影器,将参考图像的外观信息作为残差注入到扩散模型中。保持动态生成能力:该模块确保扩散模型的空间和时间生成能力不受影响,从而保留运动模块生成流畅和复杂动态细节的能力。面部表情控制:除了身体姿态控制,X-Dyna 引入了一个局部控制模块(Local Control Module),用于捕获身份解耦的面部表情。通过合成跨身份的面部表情补丁,隐式学习面部表情控制,实现更准确的表情转移。混合数据训练;X-Dyna 在人类动作视频和自然场景视频的混合数据集上进行训练。使模型能同时学习人类动作和环境动态,生成的视频不仅包含生动的人类动作,还能模拟自然环境效果(如瀑布、雨、烟花等)。- 猜你喜欢
-
 MusicTGA-HR提示指令
MusicTGA-HR提示指令 -
 RappingAI提示指令
RappingAI提示指令 -
 Boomy提示指令
Boomy提示指令 -
 TwoShot提示指令
TwoShot提示指令 -
 Weet提示指令
Weet提示指令 -
 Muzaic Studio提示指令
Muzaic Studio提示指令 -

-
 HookGen提示指令
HookGen提示指令 -
 DadaBots提示指令
DadaBots提示指令









- 相关AI应用
-
 Playlistable提示指令
Playlistable提示指令 -
 Riffusion提示指令
Riffusion提示指令 -
 WZRD提示指令
WZRD提示指令 -

-
 Cyanite.ai提示指令
Cyanite.ai提示指令 -
 Piano Genie提示指令
Piano Genie提示指令 -
 Synthesizer V提示指令
Synthesizer V提示指令 -
 Cosonify提示指令
Cosonify提示指令 -
 Musico提示指令
Musico提示指令









- 推荐AI教程资讯
- X-Dyna – 字节联合斯坦福等高校推出的动画生成框架
- DeepSeek-R1 – DeepSeek推出的高性能AI推理模型,性能对标OpenAI o1正式版
- 62人大模型公司卖了93亿元!AIGC最大收购案诞生:华人联创,两年估值翻6倍
- k1.5 – Kimi推出的多模态思考模型
- OmniThink – 浙大联合阿里通义实验室推出的深度思考机器写作框架
- AI打败AI!瑞莱智慧发布全新RealSafe,自动对齐研究员方法落地
- H-Optimus-0 – 法国初创公司Bioptimus开源的病理学AI基础模型
- Roop-Unleashed – AI换脸工具,支持批量换脸、VR换脸、直播换脸
- 书生·浦像 – 上海AI Lab 联合港中文和浙大推出的超高动态成像算法
- 北大最新研究称LK-99不是超导体!韩国作者爆料:一家科技巨头已入局研发






- 推荐阅读阅读排行
-
-





- 推荐工具精选应用
-
-
 RIFFIT Reader
RIFFIT Reader评分:4
-
 Drumloop AI
Drumloop AI评分:4
-
 ChatMindAI
ChatMindAI评分:4
-
PlaylistGenius AI
评分:4
-
 Listener.fm
Listener.fm评分:4
-



