VASA-1 – 微软推出的静态照片对口型视频生成框架
2025-05-07 13:11:48 小编:六六导航站
VASA-1是什么
VASA-1是由微软亚洲研究院提出的一个将静态照片转换为对口型动态视频的生成框架,能够根据单张静态人脸照片和一段语音音频,实时生成逼真的3D说话面部动画。该技术通过精确的唇音同步、丰富的面部表情细节和自然的头部动作,创造出高度真实感和活力的虚拟角色。VASA-1的核心创新在于其全貌面部动态和头部运动生成模型,该模型在面部潜在空间中工作,能够高效地生成高分辨率的视频,同时支持在线生成和低延迟。

VASA-1的功能特性
逼真的唇音同步:VASA-1能够生成与输入语音音频精确同步的唇部动作,提供高度逼真的说话效果。丰富的面部表情:除了唇部动作,VASA-1还能捕捉并再现一系列复杂的面部表情和微妙的情感细节,增加动画的真实感。自然头部运动:模型能够模拟自然的头部动作,如转动和倾斜,使得生成的说话面部视频更加生动。高效视频生成:VASA-1支持在线生成高达40 FPS的512×512分辨率视频,且具有极低的初始延迟,适合实时应用。灵活可控生成:通过接受可选信号作为条件,如主要目光方向、头部距离和情感偏移,VASA-1能够控制生成过程,提高输出的多样性和适应性。处理不同输入:VASA-1能够处理训练分布之外的照片和音频输入,如艺术照片、歌唱音频和非英语语音。VASA-1的官网入口
官方项目主页:https://www.microsoft.com/en-us/research/project/vasa-1/arXiv研究论文:https://arxiv.org/abs/2404.10667VASA-1的工作原理
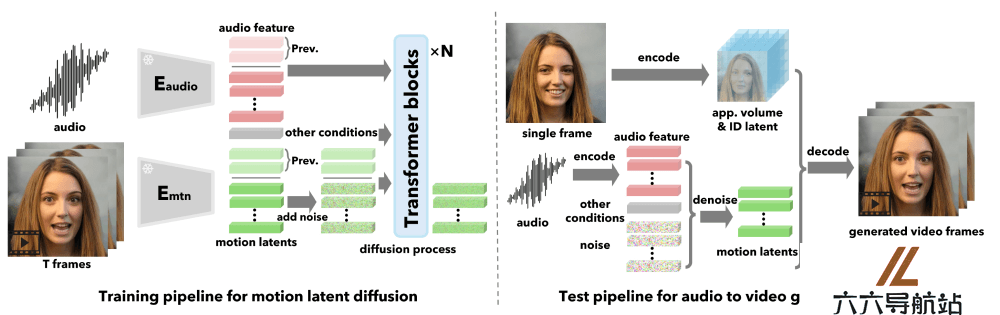 输入准备:VASA-1接受两个主要输入:一张任意个体的静态面部图像和一个来自任何个人的语音音频剪辑。面部特征提取:使用面部编码器从输入的静态面部图像中提取3D外观体积、身份代码、头部姿态和面部动态代码等特征。面部潜在空间建模:构建一个面部潜在空间,该空间能够高度解耦面部动态和其他因素(如身份和外观),并具有丰富的表情细节和动态细微差别的表达能力。扩散模型训练:训练一个基于扩散的模型(Diffusion Transformer),该模型能够在面部潜在空间中生成全面的面部动态和头部运动,条件是给定的音频和可选的控制信号。条件信号整合:将主要目光方向、头部距离和情感偏移等控制信号作为条件,输入到扩散模型中,以指导面部动态的生成。面部动态和头部运动生成:利用训练好的扩散模型,根据输入的音频特征和条件信号,生成面部动态和头部运动的潜在代码序列。视频帧生成:使用面部解码器和从编码器中提取的外观及身份特征,根据生成的面部动态和头部运动潜在代码,产生最终的视频帧。
输入准备:VASA-1接受两个主要输入:一张任意个体的静态面部图像和一个来自任何个人的语音音频剪辑。面部特征提取:使用面部编码器从输入的静态面部图像中提取3D外观体积、身份代码、头部姿态和面部动态代码等特征。面部潜在空间建模:构建一个面部潜在空间,该空间能够高度解耦面部动态和其他因素(如身份和外观),并具有丰富的表情细节和动态细微差别的表达能力。扩散模型训练:训练一个基于扩散的模型(Diffusion Transformer),该模型能够在面部潜在空间中生成全面的面部动态和头部运动,条件是给定的音频和可选的控制信号。条件信号整合:将主要目光方向、头部距离和情感偏移等控制信号作为条件,输入到扩散模型中,以指导面部动态的生成。面部动态和头部运动生成:利用训练好的扩散模型,根据输入的音频特征和条件信号,生成面部动态和头部运动的潜在代码序列。视频帧生成:使用面部解码器和从编码器中提取的外观及身份特征,根据生成的面部动态和头部运动潜在代码,产生最终的视频帧。 - 猜你喜欢
-
 MusicTGA-HR提示指令
MusicTGA-HR提示指令 -
 RappingAI提示指令
RappingAI提示指令 -
 Boomy提示指令
Boomy提示指令 -
 TwoShot提示指令
TwoShot提示指令 -
 Weet提示指令
Weet提示指令 -
 Muzaic Studio提示指令
Muzaic Studio提示指令 -

-
 HookGen提示指令
HookGen提示指令 -
 DadaBots提示指令
DadaBots提示指令









- 相关AI应用
-
 Playlistable提示指令
Playlistable提示指令 -
 Riffusion提示指令
Riffusion提示指令 -
 WZRD提示指令
WZRD提示指令 -

-
 Cyanite.ai提示指令
Cyanite.ai提示指令 -
 Piano Genie提示指令
Piano Genie提示指令 -
 Synthesizer V提示指令
Synthesizer V提示指令 -
 Cosonify提示指令
Cosonify提示指令 -
 Musico提示指令
Musico提示指令









- 推荐AI教程资讯
- VASA-1 – 微软推出的静态照片对口型视频生成框架
- Llama 3 – Meta开源推出的新一代大语言模型
- FunClip – 阿里达摩院开源的AI自动视频剪辑工具
- Phi-3 – 微软最新推出的新一代小模型系列
- CogVLM2 – 智谱AI推出的新一代多模态大模型
- GPT-4.1 – OpenAI 推出新一代语言模型,支持百万 token 上下文
- Agent Development Kit – 谷歌开源的 AI Agent 开发与部署框架
- MiniMax MCP Server – MiniMax 推出基于 MCP 的多模态生成服务器
- BiliNote – 开源 AI 视频笔记工具,自动提取视频内容生成Markdown格式
- 可灵2.0 – 快手推出的新一代AI视频生成模型
- 精选推荐
-
 Koolio.ai2025-02-19提示指令
Koolio.ai2025-02-19提示指令 -
 Superpower ChatGPT2025-02-01提示指令
Superpower ChatGPT2025-02-01提示指令 -
 Learning Prompt2025-01-02提示指令
Learning Prompt2025-01-02提示指令 -
 ChatMindAI2025-01-27提示指令
ChatMindAI2025-01-27提示指令 -
 Epagestore.ai2025-02-05法律助手
Epagestore.ai2025-02-05法律助手 -
 Soundraw2025-02-24提示指令
Soundraw2025-02-24提示指令






- 推荐阅读阅读排行
-
-
-
 MDM – 苹果推出开源的新型扩散模型框架AI教程资讯
MDM – 苹果推出开源的新型扩散模型框架AI教程资讯 -
-
-
-





- 推荐工具精选应用
-
-
Koolio.ai
评分:4
-
Superpower ChatGPT
评分:4
-
Soundraw
评分:4
-
Learning Prompt
评分:4
-
ChatMindAI
评分:4
-