SWEET-RL – Meta 推出的多轮强化学习框架
2025-05-27 09:36:32 小编:六六导航站
SWEET-RL是什么
SWEET-RL是Meta推出的多轮强化学习框架,专门用在训练大型语言模型(LLM)代理进行协作推理任务。SWEET-R基于训练时的额外信息(如参考解决方案)优化“批评者”模型,模型为每个步骤提供奖励,帮助“行动者”模型更好地分配信用、优化策略。SWEET-RL在ColBench基准测试中表现出色,相比其他先进算法,在后端编程和前端设计任务上的成功率和胜率提升6%,使Llama-3.1-8B模型的性能与GPT-4o等顶尖模型相媲美甚至超越。
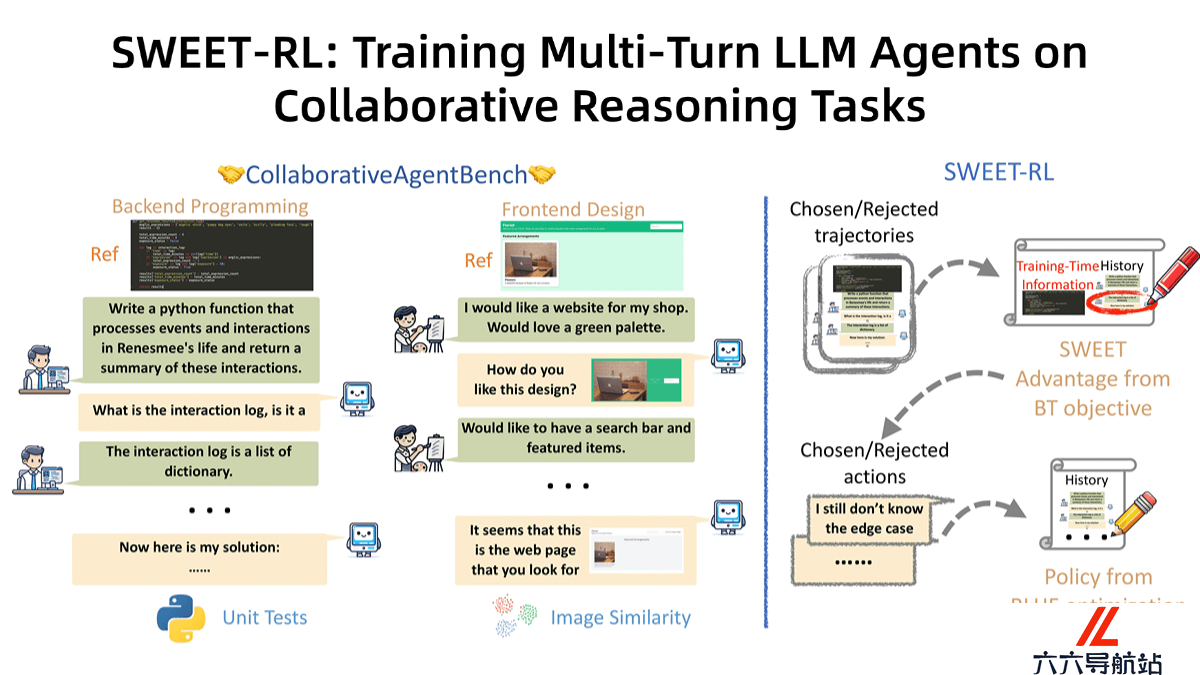
SWEET-RL的主要功能
优化多轮交互任务:SWEET-RL 专门针对需要多轮交互的复杂任务进行优化,例如后端编程和前端设计。有效分配信用:基于引入训练时的额外信息(如参考解决方案),为每个步骤提供奖励,准确地评估每个动作的价值,解决多轮任务中信用分配的难题。支持多种任务类型:支持处理复杂的前端设计任务,展现在不同类型任务中的通用性和适应性。SWEET-RL的技术原理
训练时的额外信息:SWEET-RL 基于训练时的额外信息(如参考解决方案)优化“批评者”模型。批评者模型为每个步骤提供奖励,帮助“行动者”模型更好地分配信用。Bradley-Terry 目标:SWEET-RL 用 Bradley-Terry 目标函数直接训练优势函数,优势函数评估每个动作在当前状态下的有效性。避免先训练价值函数预测当前状态和动作的期望效用,更好地与预训练的 LLM 对齐。不对称信息结构:基于不对称的演员-评论家结构,其中批评者模型访问训练时的额外信息,行动者模型访问交互历史。让批评者更准确地评估动作的价值,行动者根据评估优化策略。参数化优势函数:将优势函数参数化为每个动作的平均对数概率,基于轨迹级别的 Bradley-Terry 目标进行训练。参数化方式与 LLM 的预训练目标更一致,提高模型的泛化能力。SWEET-RL的项目地址
GitHub仓库:https://github.com/facebookresearch/sweet_rlHuggingFace模型库:https://huggingface.co/datasets/facebook/collaborative_agent_bencharXiv技术论文:https://arxiv.org/pdf/2503.15478SWEET-RL的应用场景
文本校对:帮助作者和编辑快速纠正文章中的错别字和敏感内容。社交媒体审核:确保社交媒体发布内容合规,保护个人或企业声誉。广告合规:审核广告文案,避免因内容错误导致的法律和市场风险。学术出版:确保教材和学术作品的准确性和严谨性。多媒体内容检测:审核视频、音频和图片,确保多媒体内容合法合规。- 猜你喜欢
-
 MusicTGA-HR提示指令
MusicTGA-HR提示指令 -
 RappingAI提示指令
RappingAI提示指令 -
 Boomy提示指令
Boomy提示指令 -
 TwoShot提示指令
TwoShot提示指令 -
 Weet提示指令
Weet提示指令 -
 Muzaic Studio提示指令
Muzaic Studio提示指令 -

-
 HookGen提示指令
HookGen提示指令 -
 DadaBots提示指令
DadaBots提示指令









- 相关AI应用
-
 Playlistable提示指令
Playlistable提示指令 -
 Riffusion提示指令
Riffusion提示指令 -
 WZRD提示指令
WZRD提示指令 -

-
 Cyanite.ai提示指令
Cyanite.ai提示指令 -
 Piano Genie提示指令
Piano Genie提示指令 -
 Synthesizer V提示指令
Synthesizer V提示指令 -
 Cosonify提示指令
Cosonify提示指令 -
 Musico提示指令
Musico提示指令









- 推荐AI教程资讯
- SWEET-RL – Meta 推出的多轮强化学习框架
- OThink-MR1 – OPPO联合港科大推出的多模态语言模型优化框架
- DeepSite – 基于 DeepSeek 开源的 AI 前端开发工具
- EasyControl Ghibli – 免费生成吉卜力风格图像的 AI 模型
- Dolphin – 清华联合海天瑞声推出的语音识别大模型
- WorldScore – 斯坦福大学推出的世界生成模型统一评估基准
- PaperBench – OpenAI 开源的 AI 智能体评测基准
- DreamActor-M1 – 字节跳动推出的 AI 图像动画框架
- Mini DALL·E 3 – 北京理工联合上海 AI Lab等高校推出的交互式文生图框架
- MoCha – Meta 联合滑铁卢大学推出的端到端对话角色视频生成模型
- 精选推荐
-
 Shakespeare AI Toolbar2025-02-01法律助手
Shakespeare AI Toolbar2025-02-01法律助手 -
 2233.ai2025-02-02提示指令
2233.ai2025-02-02提示指令 -
 通义千问2025-01-30提示指令
通义千问2025-01-30提示指令 -
 ChatGPT Sidebar2025-02-03提示指令
ChatGPT Sidebar2025-02-03提示指令 -
 ChatGPT Free2025-02-13提示指令
ChatGPT Free2025-02-13提示指令 -
 Databass2025-02-18提示指令
Databass2025-02-18提示指令






- 推荐阅读阅读排行
-
-





- 推荐工具精选应用
-
-
ChatGPT Free
评分:4
-
通义千问
评分:4
-
2233.ai
评分:4
-
Databass
评分:4
-
ChatGPT Sidebar
评分:4
-




