谷歌推网页爬虫新标准,开源robots.txt解析器
2025-06-22 14:48:46 小编:六六导航站
对于接触过网络爬虫的人来说 robots.txt 绝不陌生,这一存放于网站根目录下的 ASCII 码文件标明了网站中哪些内容是可以抓取的,哪些内容又是禁止抓取的。
今年,robots.txt 就满 25 周岁了, 为了给这位互联网MVP庆祝生日,谷歌再度出手,开源 robots.txt 解析器,试图推助机器人排除协议(REP)正式成为互联网行业标准。
非标准的标准
机器人排除协议(Robots Exclusion Protocol)是荷兰软件工程师 Martijn Koster 在1994 提出的一项标准,其核心就是通过 robots.txt 这样一个简单的文本文件来控制爬虫机器人的行为。
REP 以其简单高效征服了互联网行业,有超过 5 亿个网站都在使用 robots.txt,可以说它已经成为了限制爬虫的事实标准,像 Googlebot 在抓取网页时就会
- 猜你喜欢
-
 MusicTGA-HR提示指令
MusicTGA-HR提示指令 -
 RappingAI提示指令
RappingAI提示指令 -
 Boomy提示指令
Boomy提示指令 -
 TwoShot提示指令
TwoShot提示指令 -
 Weet提示指令
Weet提示指令 -
 Muzaic Studio提示指令
Muzaic Studio提示指令 -

-
 HookGen提示指令
HookGen提示指令 -
 DadaBots提示指令
DadaBots提示指令









- 相关AI应用
-
 Playlistable提示指令
Playlistable提示指令 -
 Riffusion提示指令
Riffusion提示指令 -
 WZRD提示指令
WZRD提示指令 -

-
 Cyanite.ai提示指令
Cyanite.ai提示指令 -
 Piano Genie提示指令
Piano Genie提示指令 -
 Synthesizer V提示指令
Synthesizer V提示指令 -
 Cosonify提示指令
Cosonify提示指令 -
 Musico提示指令
Musico提示指令









- 推荐AI教程资讯
- 谷歌推网页爬虫新标准,开源robots.txt解析器
- 全程中文!谷歌发布机器学习速成课,完全免费(附视听评测)
- 亚马逊员工流动率150%,每8个月相当于“大换血”,网友:贝佐斯不知足
- ICLR 2021杰出论文奖公布,DeepMind是最大赢家
- DeepMind开通AI播客,哈萨比斯参与录制,让你在碎片时间听懂AI
- 谷歌用新AI超越自己:让Imagen能够指定生成对象,风格还能随意转换
- 苹果为了不让AirTag被用来跟踪,将推出一个安卓应用
- 魔改宜家灯泡当主机,玩转《毁灭战士》无压力!网友:远超我家第一台电脑
- 她用ChatGPT写了一篇文章,日赚14000元!
- 光缆能预警地震?谷歌做到了!140万公里海缆有望成为报警器






- 推荐阅读阅读排行
-
-

-
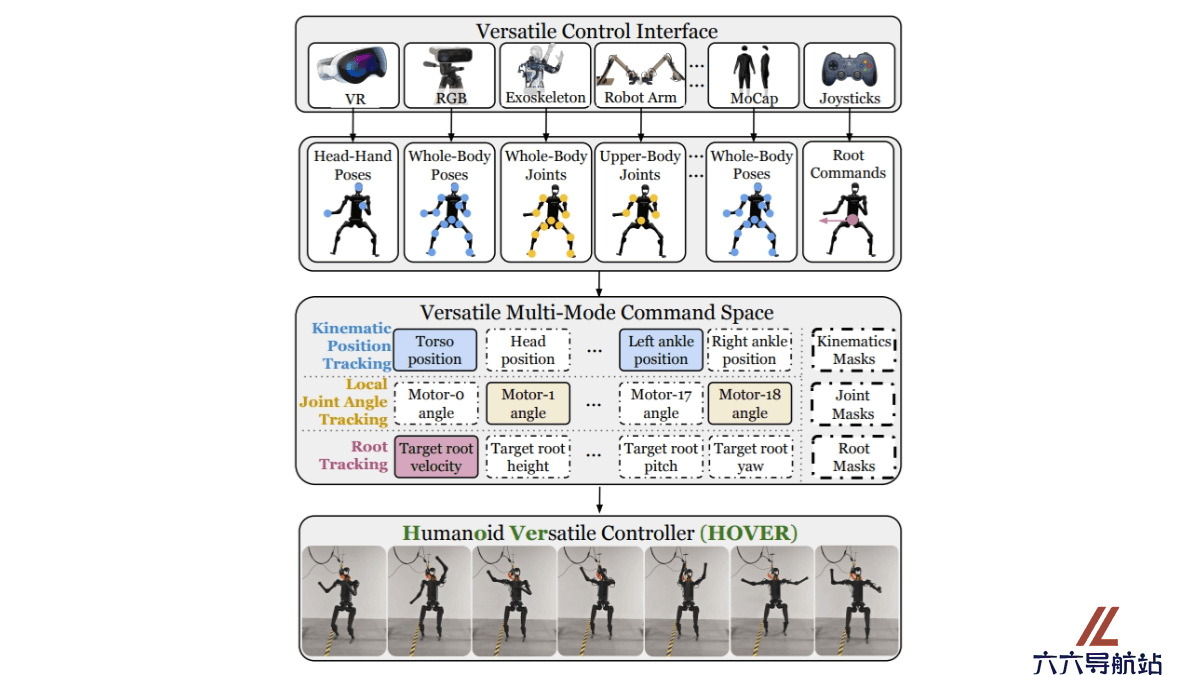
-

-
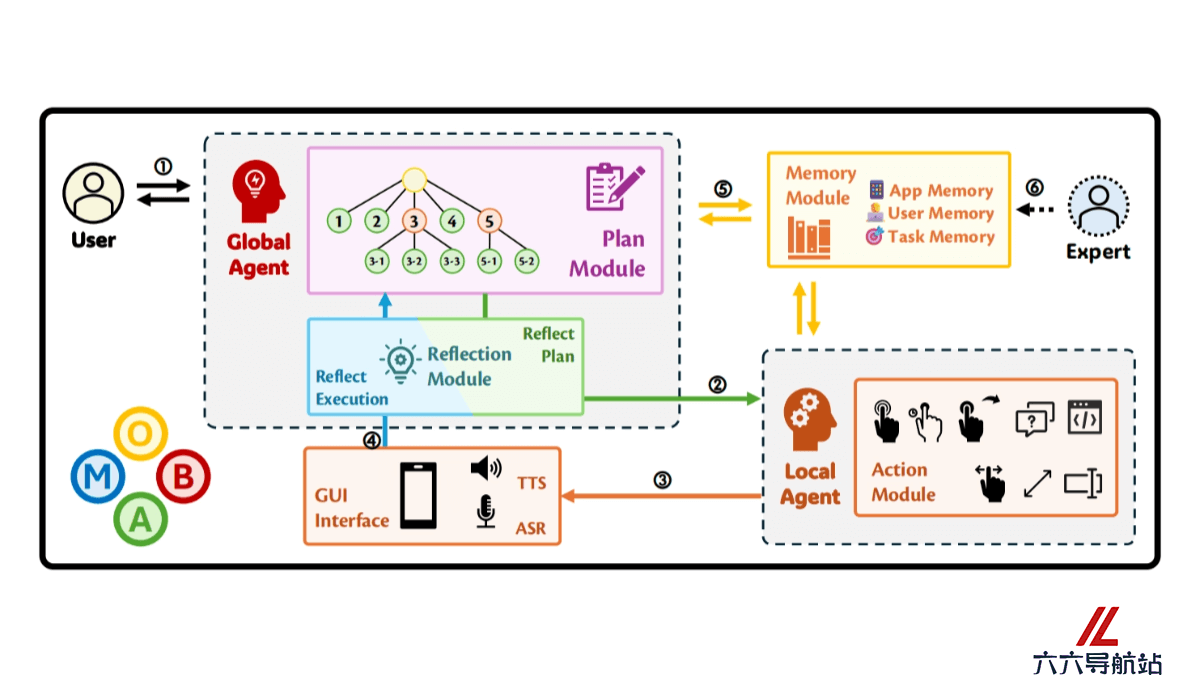 MobA – 上海交通大学推出的移动智能体AI教程资讯
MobA – 上海交通大学推出的移动智能体AI教程资讯 -
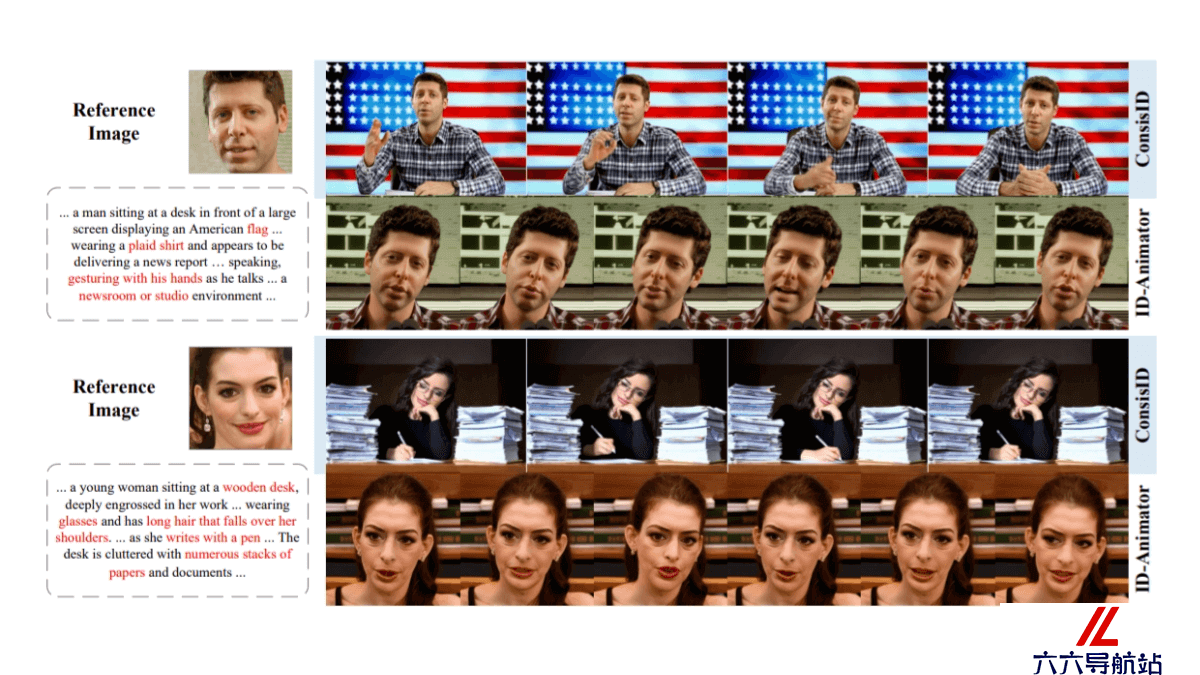
-








- 推荐工具精选应用
-
-
 Ghostwrite
Ghostwrite评分:4
-
 Altered
Altered评分:4
-
 AskGPT
AskGPT评分:4
-
 提示工程指南
提示工程指南评分:4
-
 Chord ai
Chord ai评分:4
-

