MSQA – 大规模多模态3D情境推理数据集
2025-01-24 13:03:52 小编:六六导航站
MSQA是什么
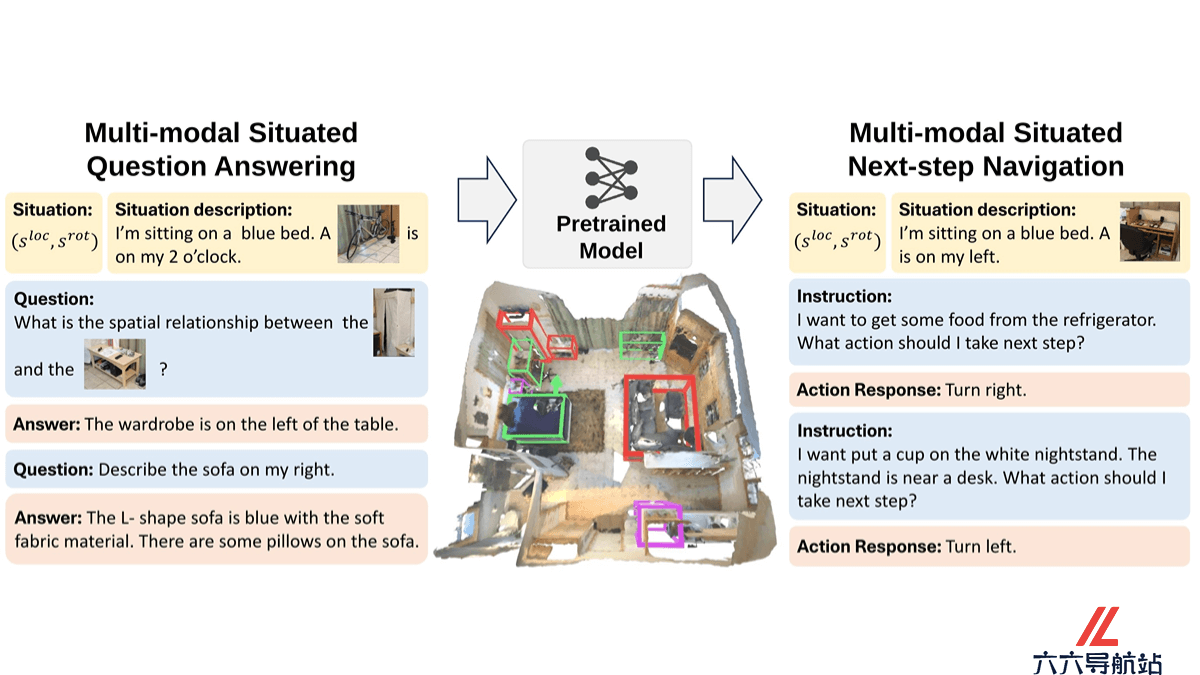
MSQA(Multi-modal Situated Question Answering)是大规模多模态情境推理数据集,提升具身AI代理在3D场景中的理解与推理能力。数据集包含251K个问答对,覆盖9个问题类别,基于3D场景图和视觉-语言模型在真实世界3D场景中收集。MSQA用文本、图像和点云的交错多模态输入,减少单模态输入的歧义。引入MSNN(Multi-modal Next-step Navigation)基准测试,评估模型在情境间导航的能力,有助于开发更强大的情境推理模型,推动3D场景理解技术的发展。
MSQA的主要功能
多模态情境推理:MSQA提供包含251K个问答对的数据集,问答对覆盖9个不同的问题类别,涉及3D场景中的复杂情境和对象模态。数据模态的多样性:支持文本、图像和点云等多种数据模态,提供更全面的情境描述,减少单模态输入的局限性和歧义。评估模型性能:设计MSQA和MSNN两个基准测试任务,评估和比较不同模型在3D场景中的情境推理和导航能力。促进AI研究:基于提供大规模的多模态数据集,MSQA推动了具身AI和3D场景理解领域的研究进展。预训练和模型开发:MSQA数据集作为预训练材料,帮助开发和优化更强大的情境推理模型。MSQA的技术原理
数据收集与生成:用3D场景图和视觉-语言模型(VLMs)在真实世界的3D场景中自动且可扩展地收集数据。多模态输入设置:引入交错多模态输入,结合文本、图像和点云数据,提供更准确的情境和问题描述。情境意识建模:整合不同模态的输入数据,提高模型对情境的感知和理解能力。评估基准测试设计:设计MSQA和MSNN两个基准测试,分别针对情境问答和下一步导航任务,全面评估模型的多模态理解和情境推理能力。模型评估与分析:在MSQA和MSNN上进行实验,分析现有模型的局限性,探索处理多模态输入和情境建模的重要性。MSQA的项目地址
项目官网:msr3d.github.ioarXiv技术论文:https://arxiv.org/pdf/2409.02389MSQA的应用场景
智能导航系统:在室内或室外环境中,帮助开发理解复杂空间关系,提供导航指令的智能系统。增强现实(AR)和虚拟现实(VR):在AR和VR应用中,提供对虚拟环境的深入理解和交互,提升用户体验。机器人交互:使机器人理解和响应关于其周围环境的问题,提高其在复杂3D空间中的操作和交互能力。自动驾驶车辆:辅助自动驾驶车辆理解交通场景,提供更准确的决策支持,应对复杂的道路状况。智能助理和聊天机器人:理解用户的3D空间查询,提供更准确和上下文相关的回答。- 猜你喜欢
-
 词魂提示指令
词魂提示指令 -
 ChatGPT Shortcut提示指令
ChatGPT Shortcut提示指令 -
 Learning Prompt提示指令
Learning Prompt提示指令 -

-
 PromptVine提示指令
PromptVine提示指令 -

-

-
 MJ Prompt Tool提示指令
MJ Prompt Tool提示指令 -
 绘AI提示指令
绘AI提示指令









- 相关AI应用
-
 AIPRM提示指令
AIPRM提示指令 -
 Snack Prompt提示指令
Snack Prompt提示指令 -
 PublicPrompts提示指令
PublicPrompts提示指令 -
 Generrated提示指令
Generrated提示指令 -
 LangGPT提示指令
LangGPT提示指令 -
 AI Short提示指令
AI Short提示指令 -

-
 ClickPrompt提示指令
ClickPrompt提示指令 -
 PromptHero提示指令
PromptHero提示指令









- 推荐AI教程资讯
- MSQA – 大规模多模态3D情境推理数据集
- Excalidraw – 开源的在线白板工具,手绘风格实时协作
- RMBG-2.0 – 开源的图像背景移除模型,支持各类图像高精度背景移除
- JanusFlow – DeepSeek开源多模态理解与生成任务统一的框架
- SWE-Kit – 构建自定义软件工程AI代理的开源框架
- Text Behind Image – 开源在线图像处理工具,在图中角色背后添加文字
- 云锦天章 – 彩云科技推出的基于DCFormer架构通用大模型
- MikuDance – 混合动力动画生成技术,将静态图像生成动态风格化的角色艺术
- MATRIX-Gen – 上海交大联合牛津大学推出的多智能体模拟系统
- BodyTalk – AI视频配音工具,自动适配新语音的唇形、面部表情和肢体动作


- 推荐阅读阅读排行
-
-





