MM1.5 – 苹果推出的升级版多模态大模型
2025-02-05 18:07:25 小编:六六导航站
MM1.5是什么
MM1.5是苹果公司推出的多模态大型语言模型,旨在增强文本丰富图像理解、视觉指代和定位以及多图像推理能力。模型基于数据为中心的训练方法,在大规模预训练、高分辨率OCR数据持续预训练及优化的视觉指令微调,实现从1B到30B参数规模的高性能。MM1.5包括密集型和MoE变体,展现小规模模型通过精细数据策划和训练策略达到强大性能。MM1.5推出针对视频理解和移动UI理解优化的专门变体MM1.5-Video和MM1.5-UI,基于实证研究提供训练过程和决策的深入见解,为多模态AI技术的未来发展提供指导。
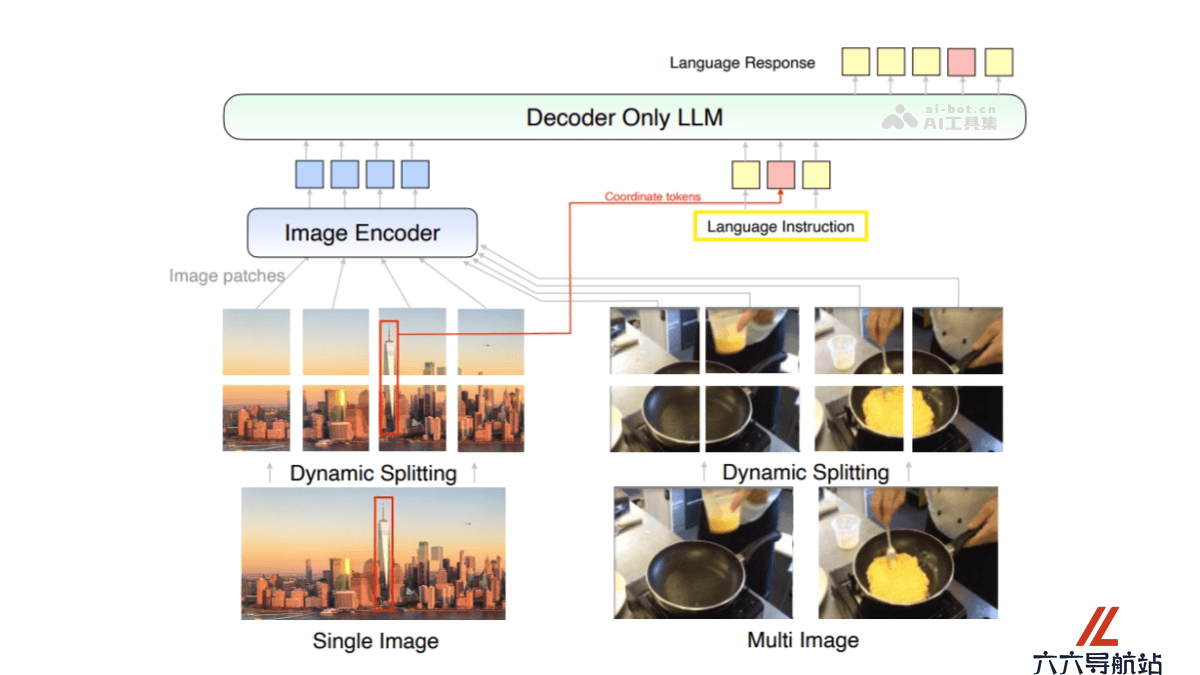
MM1.5的主要功能
文本丰富的图像理解:MM1.5能理解图像中的文本内容以及文本与图像内容之间的关系。视觉指代和定位:模型识别图像中的特定对象,理解文本中对对象的引用,如“那个红色的球”。多图像推理:MM1.5能分析多张图像,理解图像之间的联系,进行逻辑推理。视频理解:基于MM1.5-Video变体,模型能理解视频内容,包括动作、事件和时间序列。移动UI理解:MM1.5-UI变体专门针对移动应用界面的理解,识别和操作界面元素。MM1.5的技术原理
深度学习和自然语言处理:结合深度学习的视觉模型和自然语言处理技术,模型能理解和生成与图像内容相关的文本。坐标token和视觉注意力机制:用坐标token定位图像中的对象,基于视觉注意力机制关注图像的特定区域。图像分割和多模态融合:将图像分割成多个部分,与文本信息融合,支持多图像推理。视频帧采样和时序分析:对视频帧进行采样,分析帧之间的时序关系,理解视频内容。界面元素识别:用图像识别技术识别移动界面上的元素,如按钮和图标。MM1.5的项目地址
arXiv技术论文:https://arxiv.org/pdf/2409.20566v1MM1.5的应用场景
图像和视频理解:MM1.5能理解和分析图像及视频内容,应用于图像标注、视频内容分析、安防监控等领域。视觉搜索:在电子商务或数字图书馆中,MM1.5帮助用户基于描述或查询图像来搜索特定的产品或文档。辅助驾驶和自动驾驶:在汽车行业,MM1.5用在理解和分析道路情况,辅助驾驶决策。智能助手:在智能手机和智能家居设备中,MM1.5提供更自然、直观的交互方式,理解用户的语音或文本指令。教育和培训:MM1.5作为教育工具,帮助学生理解复杂的概念,提供个性化的学习体验。- 猜你喜欢
-
 悟智写作提示指令
悟智写作提示指令 -

-
 BraveGPT提示指令
BraveGPT提示指令 -
 ChatGPT Sidebar提示指令
ChatGPT Sidebar提示指令 -
 Prompt Genie提示指令
Prompt Genie提示指令 -
 RoleD提示指令
RoleD提示指令 -
 2233.ai提示指令
2233.ai提示指令 -

-










- 相关AI应用
-
 Minigpt提示指令
Minigpt提示指令 -
 PromptStacks提示指令
PromptStacks提示指令 -
 AskGPT提示指令
AskGPT提示指令 -

-
 ContentGeni提示指令
ContentGeni提示指令 -
 Call Annie提示指令
Call Annie提示指令 -
 ChatGenius提示指令
ChatGenius提示指令 -
 通义千问提示指令
通义千问提示指令 -
 知否AI问答提示指令
知否AI问答提示指令









- 推荐AI教程资讯
- MM1.5 – 苹果推出的升级版多模态大模型
- Surya – 开源的OCR工具包,支持90+语言、布局分析等识别
- Illuminate – 谷歌推出将学术论文转化为音频讨论的AI项目
- Loong – 港大和字节联合推出的长视频生成模型
- ScriptViz – 斯坦福大学推出的剧本可视化AI辅助工具
- MLE-bench – OpenAI推出AI代理性能评估的基准测试工具
- GTSinger – 浙大开源的大型多语言高质量歌声数据集
- LightRAG – 香港大学推出的开源检索增强生成系统
- Gen2Act – 谷歌、卡内基梅隆、斯坦福联合推出生成人类视频引导机器人操作策略
- T2V-Turbo – 谷歌开源的文本到视频生成模型




- 推荐阅读阅读排行
-
-





- 推荐工具精选应用
-
-
 词魂
词魂评分:4
-
 豆包AI助手 ( 免费 )
豆包AI助手 ( 免费 )评分:4
-
-
 Snack Prompt
Snack Prompt评分:4
-
 文心一言
文心一言评分:4
-


