Mini-LLaVA – 基于Llama 3.1的轻量级多模态大语言模型
2025-02-08 15:56:34 小编:六六导航站
Mini-LLaVA是什么
Mini-LLaVA是一款轻量级的多模态大语言模型,由清华大学和北京航空航天大学的研究团队联合开发。能处理图像、文本和视频输入,实现高效的多模态数据处理。Mini-LLaVA基于Llama 3.1模型,优化了代码结构,在单个GPU上即可运行,适合复杂的视觉-文本关联任务。项目已在GitHub上开源,便于研究者和开发者下载使用。Mini-LLaVA的设计注重代码的可读性和功能的扩展性,支持定制和微调,适应不同的应用场景。
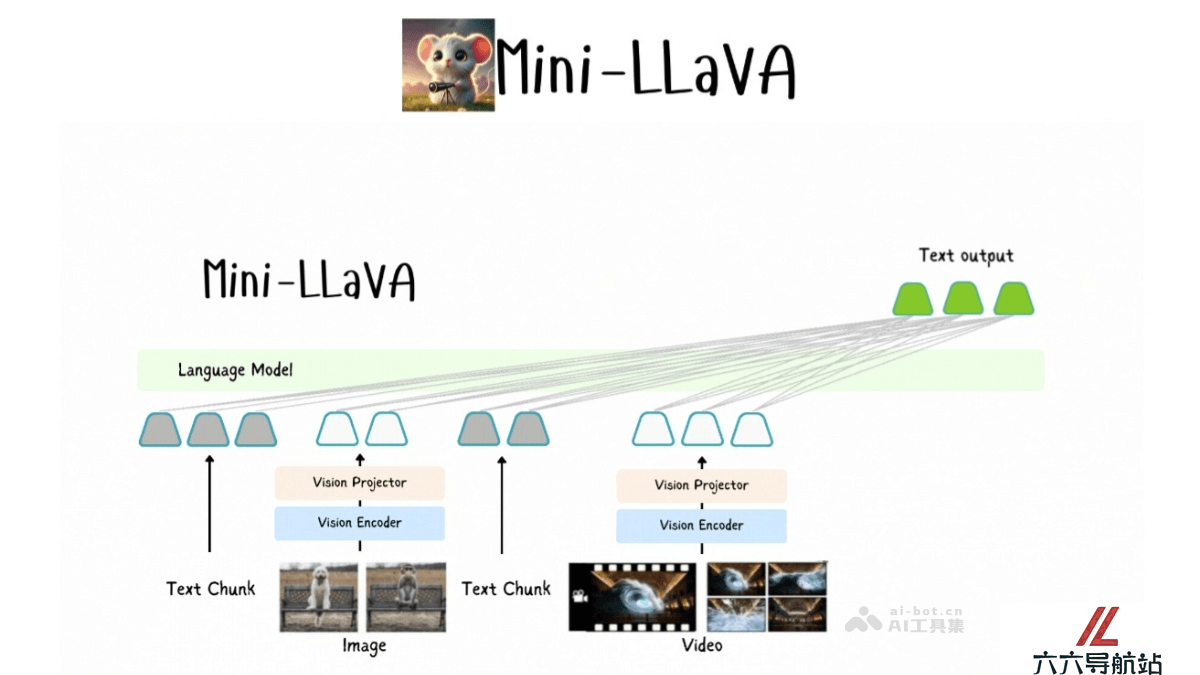
Mini-LLaVA的主要功能
图像理解:模型分析图像内容,根据图像内容生成描述或回答相关问题。视频分析:Mini-LLaVA能处理视频数据,理解视频内容,并提供相应的文本输出。文本生成:基于输入的图像或视频,模型生成相关的文本描述或总结。视觉-文本关联:模型能理解图像和文本之间的关联,并在生成的文本中反映这种关系。灵活性:基于其轻量级和简化的代码结构,Mini-LLaVA能在资源有限的环境中部署,如单个GPU。Mini-LLaVA的技术原理
多模态输入处理:Mini-LLaVA能够接收和处理多种类型的输入,包括文本、图像和视频。集成视觉编码器和语言解码器,实现对不同模态数据的理解和分析。基于Llama 3.1:基于Llama 3.1模型,通过额外的训练和调整,具备处理视觉数据的能力。简化的代码结构:Mini-LLaVA的代码设计注重简洁,使模型更容易理解和修改。交错处理:模型支持交错处理图像、视频和文本,在保持输入顺序的同时,对不同模态的数据进行分析和响应。预训练适配器:Mini-LLaVA基于预训练的适配器增强Llama 3.1模型的视觉处理能力,允许模型更好地理解和生成与输入相关的输出。Mini-LLaVA的项目地址
GitHub仓库:https://github.com/fangyuan-ksgk/Mini-LLaVAMini-LLaVA的应用场景
教育与培训:作为教学工具,帮助学生理解复杂的概念,通过图像、视频和文本的结合提供丰富的学习体验。内容创作:辅助内容创作者生成图像描述、视频字幕或自动化地生成文章和报告。媒体与娱乐:在电影、游戏和视频制作中,生成剧本、角色对话或自动生成视频内容的描述。智能助手:作为聊天机器人或虚拟助手的一部分,提供图像和视频理解能力,更好地与用户互动。社交媒体分析:分析社交媒体上的图像和视频内容,提取关键信息,帮助品牌和个人了解公众对内容的反应。安全监控:在安全领域,对监控视频进行实时分析,识别异常行为或事件。- 猜你喜欢
-
 Chad GPT提示指令
Chad GPT提示指令 -
 Valideo提示指令
Valideo提示指令 -
 GPT Stylist提示指令
GPT Stylist提示指令 -

-

-
 FictionGPT提示指令
FictionGPT提示指令 -

-
 Embra提示指令
Embra提示指令 -
 ChatGPT Super提示指令
ChatGPT Super提示指令









- 相关AI应用
-
 DapperGPT提示指令
DapperGPT提示指令 -
 IMI Prompt提示指令
IMI Prompt提示指令 -
Enhanced ChatGPT提示指令
-
 Ghostwrite提示指令
Ghostwrite提示指令 -
 悟智写作提示指令
悟智写作提示指令 -

-
 BraveGPT提示指令
BraveGPT提示指令 -
 ChatGPT Sidebar提示指令
ChatGPT Sidebar提示指令 -
 Prompt Genie提示指令
Prompt Genie提示指令








- 推荐AI教程资讯
- Mini-LLaVA – 基于Llama 3.1的轻量级多模态大语言模型
- MemoryScope – 为LLM聊天机器人配备的长期记忆系统
- CogView3 – 智谱AI推出的开源AI图像生成模型
- RTranslator – 开源的离线、实时、多语言翻译应用程序
- Molmo 72B – 开源的多模态AI模型,基于Qwen2-72B模型,超越Llama 3.2
- ProX – 提高大语言模型预训练数据质量的框架
- OutofFocus – 文本驱动图像生成或编辑的AI工具
- TeleChat2-115B – 中国电信AI研究院推出的开源星辰语义大模型
- GroundingBooth – Adobe联合多所高校推出主题和文本到图像的定制框架
- markmap – 解析Markdown生成可视化思维导图的工具
- 精选推荐
-
 词魂2025-01-02提示指令
词魂2025-01-02提示指令 -
 法智2025-01-02法律助手
法智2025-01-02法律助手 -
 AI Sentence Generator2025-02-06法律助手
AI Sentence Generator2025-02-06法律助手 -
BraveGPT2025-02-05提示指令
-
 UndetectableGPT2025-01-29法律助手
UndetectableGPT2025-01-29法律助手 -
 ChatGPT Prompt Genius2025-01-02提示指令
ChatGPT Prompt Genius2025-01-02提示指令





- 推荐阅读阅读排行
-
-





- 推荐工具精选应用
-
-
词魂
评分:4
-
 ChatMindAI
ChatMindAI评分:4
-
 PromptStacks
PromptStacks评分:4
-
Embra
评分:4
-
 LangGPT
LangGPT评分:4
-


