EzAudio – 腾讯联合约翰霍普金斯大学推出的文本到音频生成模型
2025-02-10 15:21:42 小编:六六导航站
EzAudio是什么
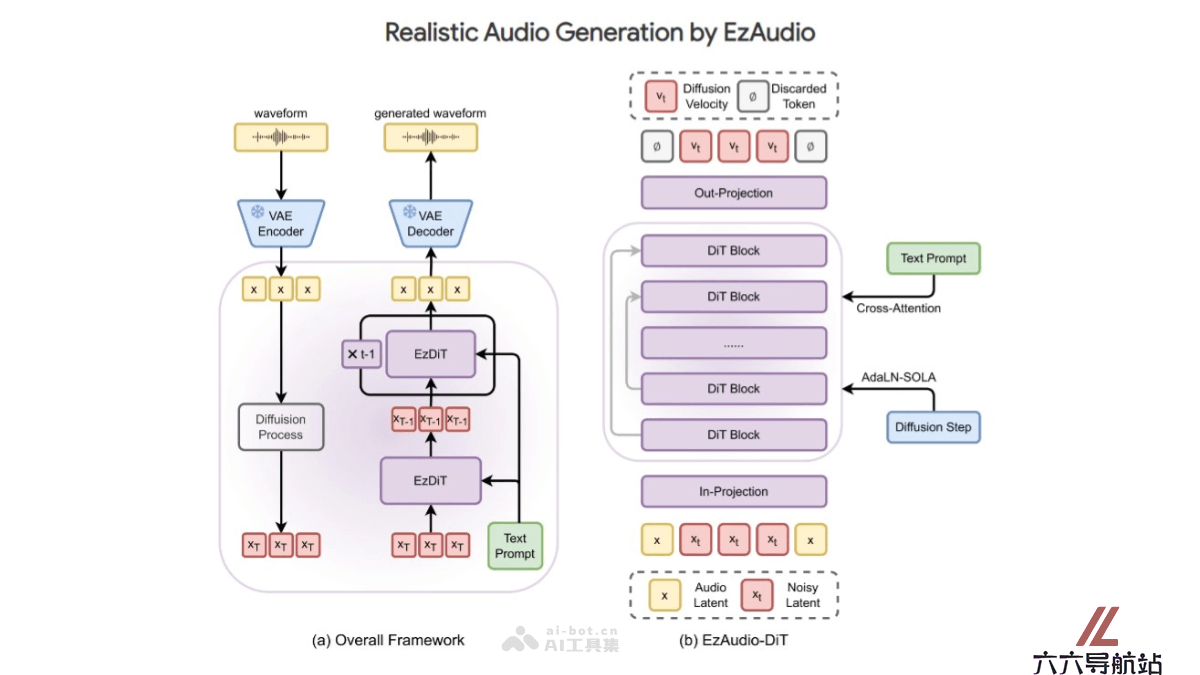
EzAudio是由约翰霍普金斯大学和腾讯AI实验室共同推出的一款文本到音频(Text-to-Audio, T2A)生成模型。基于一种高效的扩散变换器技术,用在从文本提示生成高质量的音频效果。EzAudio的创新之处在于优化的模型架构和数据高效训练策略,在生成速度、效率和音频真实感方面都达到新标准。EzAudio引入无分类器引导重缩放技术,简化模型使用保持音频质量。
- 猜你喜欢
-
 ClipGPT提示指令
ClipGPT提示指令 -
 Ogen AI提示指令
Ogen AI提示指令 -
 ChatPPT提示指令
ChatPPT提示指令 -
 Chad GPT提示指令
Chad GPT提示指令 -
 Valideo提示指令
Valideo提示指令 -
 GPT Stylist提示指令
GPT Stylist提示指令 -

-

-
 FictionGPT提示指令
FictionGPT提示指令









- 相关AI应用
-

-
 Embra提示指令
Embra提示指令 -
 ChatGPT Super提示指令
ChatGPT Super提示指令 -
 DapperGPT提示指令
DapperGPT提示指令 -
 IMI Prompt提示指令
IMI Prompt提示指令 -
Enhanced ChatGPT提示指令
-
 Ghostwrite提示指令
Ghostwrite提示指令 -
 悟智写作提示指令
悟智写作提示指令 -









- 推荐AI教程资讯
- EzAudio – 腾讯联合约翰霍普金斯大学推出的文本到音频生成模型
- FLUX-Controlnet-Inpainting – 阿里妈妈推出的开源AI图像修复工具
- Rope – 基于深度学习模型开源的AI换脸技术
- Westlake-Omni – 西湖心辰开源的中文情感端到端语音交互模型
- AutoGen Studio – 微软开源的零代码构建多智能体系统的AI工具
- IDIFY – 开源的在线AI证件照生成工具,本地浏览器自动处理图片
- Emu3 – 北京智源推出的统一输入与生成多模态模型
- CCI 3.0 – 智源研究院发布的大规模的中文互联网语料库
- MemFree – 开源的混合AI搜索引擎,支持多模态搜索和提问
- GarDiff – AI虚拟试穿技术,生成高保真试穿图像保留服装细节





- 推荐阅读阅读排行
-
-





- 推荐工具精选应用
-
-
 词魂
词魂评分:4
-
 豆包AI助手 ( 免费 )
豆包AI助手 ( 免费 )评分:4
-

-
-
 Snack Prompt
Snack Prompt评分:4
-


