Mini-Omni – 开源的端到端实时语音对话大模型
2025-02-17 10:04:22 小编:六六导航站
Mini-Omni是什么
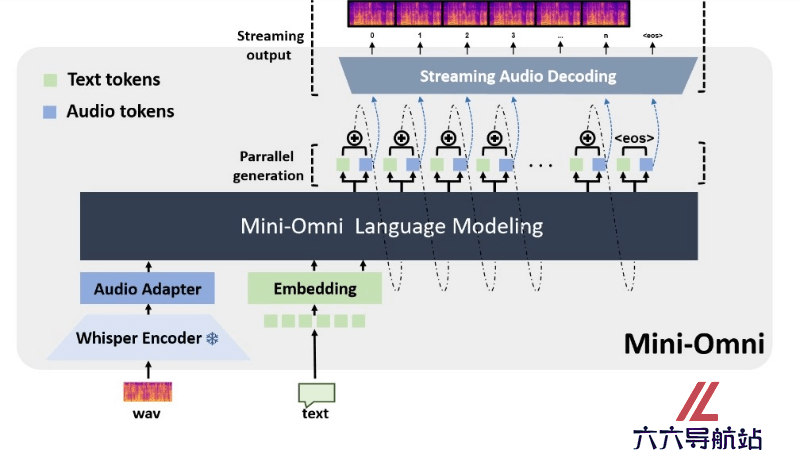
Mini-Omni 是一个开源的端到端语音对话模型,具备实时语音输入和输出的能力,能在对话中实现“边思考边说话”的功能。模型的设计支持在不需要额外的自动语音识别(ASR)或文本到语音(TTS)系统的情况下,直接进行语音到语音的对话。Mini-Omni 采用了一种文本指导的语音生成方法,通过批量并行策略在推理过程中提高性能,同时保持了原始模型的语言能力。
Mini-Omni的主要功能
实时语音交互:能进行端到端的实时语音对话,无需依赖额外的自动语音识别(ASR)或文本到语音(TTS)系统。文本和语音并行生成:在推理过程中,模型可以同时生成文本和语音输出,通过文本信息指导语音生成,提高了语音交互的自然性和流畅性。批量并行推理:采用批量并行策略,提升了模型在流式音频输出时的推理能力,使语音响应更加丰富和准确。音频语言建模:将连续的语音信号转换为离散的音频tokens,使大型语言模型能进行音频模态的推理和交互。跨模态理解:模型能理解和处理多种模态的输入,包括文本和音频,实现了跨模态的交互能力。Mini-Omni的技术原理
端到端架构:Mini-Omni采用端到端的设计,能直接处理从音频输入到文本和音频输出的整个流程,无需传统的分离式ASR和TTS系统的介入。文本指导的语音生成:模型在生成语音输出时,会先生成相应的文本信息,然后基于文本信息来指导语音的合成。基于语言模型在文本处理上的强大能力,提高语音生成的质量和自然度。并行生成策略:Mini-Omni采用并行生成策略,在推理过程中同时生成文本和音频tokens。策略支持模型在生成语音的同时保持对文本内容的理解和推理,实现更连贯和一致的对话。批量并行推理:为进一步提升模型的推理能力,Mini-Omni采用了批量并行推理策略。在策略中,模型会同时处理多个输入,通过文本生成来增强音频生成的质量。音频编码和解码:Mini-Omni使用音频编码器(如Whisper)将连续的语音信号转换为离散的音频tokens,然后通过音频解码器(如SNAC)将这些tokens转换回音频信号。Mini-Omni的项目地址
Github仓库:https://github.com/gpt-omni/mini-omniHuggingFace模型库:https://huggingface.co/gpt-omni/mini-omniarXiv技术论文:https://arxiv.org/pdf/2408.16725Mini-Omni的应用场景
智能助手和虚拟助手:在智能手机、平板电脑和电脑上,Mini-Omni可以作为一个智能助手,通过语音交互帮助用户执行任务,如设置提醒、查询信息、控制设备等。客户服务:在客户服务领域,Mini-Omni可以作为聊天机器人或语音助手,提供24/7的自动客户支持,处理咨询、解决问题和执行交易。智能家居控制:在智能家居系统中,Mini-Omni可以通过语音命令控制家中的智能设备,如灯光、温度、安全系统等。教育和培训:Mini-Omni可以作为教育工具,提供语音交互式的学习体验,帮助学生学习语言、历史或其他科目。车载系统:在汽车中,Mini-Omni可以集成到车载信息娱乐系统中,提供语音控制的导航、音乐播放、通讯等功能。- 猜你喜欢
-

-
 Drumloop AI提示指令
Drumloop AI提示指令 -
 Altered提示指令
Altered提示指令 -
 Voicemod提示指令
Voicemod提示指令 -
 AudioNotes提示指令
AudioNotes提示指令 -
 Beatoven.ai提示指令
Beatoven.ai提示指令 -
 SpeechGen提示指令
SpeechGen提示指令 -
 Voice.ai提示指令
Voice.ai提示指令 -
 Lalal.ai提示指令
Lalal.ai提示指令









- 相关AI应用
-
 Voiceful.io提示指令
Voiceful.io提示指令 -
 Voice AI提示指令
Voice AI提示指令 -
 Vocal Remover提示指令
Vocal Remover提示指令 -
 ChatGPT Free提示指令
ChatGPT Free提示指令 -
 chatnio提示指令
chatnio提示指令 -
 NineF AI提示指令
NineF AI提示指令 -
 ChatGPT Gratis提示指令
ChatGPT Gratis提示指令 -

-
 Entar.io提示指令
Entar.io提示指令









- 推荐AI教程资讯
- Mini-Omni – 开源的端到端实时语音对话大模型
- Composio – AI智能体开发辅助工具,提供100+集成工具简化开发流程
- DeepSeek-V2.5 – DeepSeek开源的融合通用和代码能力的AI模型
- MLE-Agent – 工程师的AI智能助手,自动创建基线模型
- ViewCrafter – 北大、港中文联合腾讯提出的高保真新视图合成技术
- FluxMusic – 开源的AI音乐生成模型,通过文本描述创造音乐
- LightEval – Hugging Face推出的轻量级AI大模型评估工具
- RegionDrag – 港大和牛津联合开发的基于区域的图像编辑技术
- LinFusion – 新加坡国立推出图像生成模型,单GPU一分钟生成16K图像
- Deepfake Defenders – 中科院开发的识别Deepfake伪造内容的AI模型





- 推荐阅读阅读排行
-
-








