Qwen2-VL – 阿里巴巴达摩院开源的视觉多模态AI模型
2025-02-19 10:37:28 小编:六六导航站
Qwen2-VL是什么
Qwen2-VL是阿里巴巴达摩院开源的视觉多模态AI模型,具备高级图像和视频理解能力。Qwen2-VL支持多种语言,能处理不同分辨率和长宽比的图片,实时分析动态视频内容。Qwen2-VL在多语言文本理解、文档理解等任务上表现卓越,适用于多模态应用开发,推动了AI在视觉理解和内容生成领域的进步。

Qwen2-VL的主要功能
图像理解:显著提高模型理解和解释视觉信息的能力,为图像识别和分析设定新的性能基准。视频理解:具有卓越的在线流媒体功能,能实时分析动态视频内容,理解视频信息。多语言支持:扩展了语言能力,支持中文、英文、日文、韩文等多种语言,服务于全球用户。可视化代理:集成了复杂的系统集成功能,模型能够进行复杂推理和决策。动态分辨率支持:能够处理任意分辨率的图像,无需将图像分割成块,更接近人类视觉感知。多模态旋转位置嵌入(M-ROPE):创新的嵌入技术,模型能够同时捕获和整合文本、视觉和视频位置信息。模型微调:提供微调框架,支持开发者根据特定需求调整模型性能。推理能力:支持模型推理,支持用户基于模型进行自定义应用开发。开源和API支持:模型开源,提供API接口,便于开发者集成和使用。Qwen2-VL的技术原理
多模态学习能力:Qwen2-VL设计用于同时处理和理解文本、图像和视频等多种类型的数据,要求模型能够在不同模态之间建立联系和理解。原生动态分辨率支持:Qwen2-VL能处理任意分辨率的图像输入,不同大小的图片可以被转换成动态数量的tokens,模拟了人类视觉感知的自然方式,支持模型处理任意尺寸的图像。多模态旋转位置嵌入(M-ROPE):创新的位置编码技术,将传统的旋转位置嵌入分解为代表时间、高度和宽度的三个部分,使模型能够同时捕捉和整合一维文本序列、二维视觉图像以及三维视频的位置信息。变换器架构:Qwen2-VL采用了变换器(Transformer)架构,在自然语言处理领域广泛使用的模型架构,特别适合处理序列数据,并且能够通过自注意力机制捕捉长距离依赖关系。注意力机制:模型使用自注意力机制来加强不同模态数据之间的关联,模型能更好地理解输入数据的上下文信息。预训练和微调:Qwen2-VL通过在大量数据上进行预训练来学习通用的特征表示,然后通过微调来适应特定的应用场景或任务。量化技术:为了提高模型的部署效率,Qwen2-VL采用了量化技术,将模型的权重和激活从浮点数转换为较低精度的表示,以减少模型的大小和提高推理速度。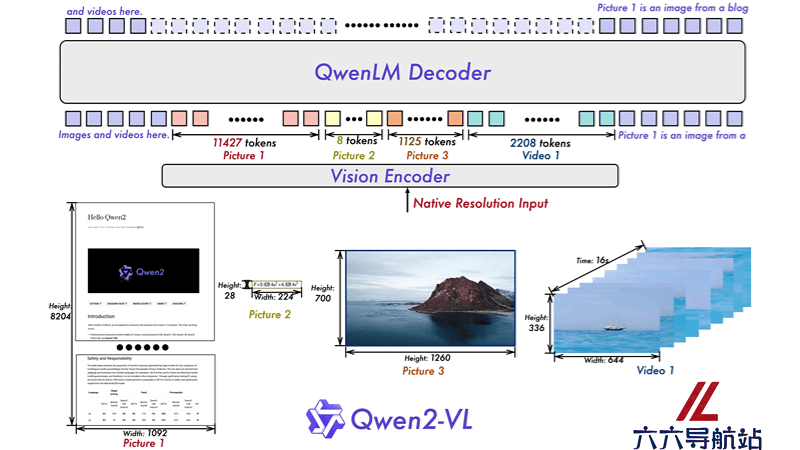
Qwen2-VL性能指标
模型规模性能对比:72B规模模型:在多个指标上达到最优,甚至超过了GPT-4o和Claude3.5-Sonnet等闭源模型,特别是在文档理解方面表现突出,但在综合大学题目上与GPT-4o有一定差距。7B规模模型:在成本效益和性能之间取得平衡,支持图像、多图、视频输入,在文档理解能力和多语言文字理解能力方面处于最前沿水平。2B规模模型:为移动端应用优化,具备完整的图像视频多语言理解能力,在视频文档理解和通用场景问答方面相比同规模模型有明显优势。多分辨率图像理解:Qwen2-VL在视觉理解基准测试如MathVista、DocVQA、RealWorldQA、MTVQA中取得了全球领先的表现,显示出其能够理解不同分辨率和长宽比的图片。长视频内容理解:Qwen2-VL能够理解长达20分钟的视频内容,这使得它在视频问答、对话和内容创作等应用场景中表现出色。多语言文本理解:除了英语和中文,Qwen2-VL还支持理解图像中的多语言文本,包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等,这增强了其全球范围内的应用潜力。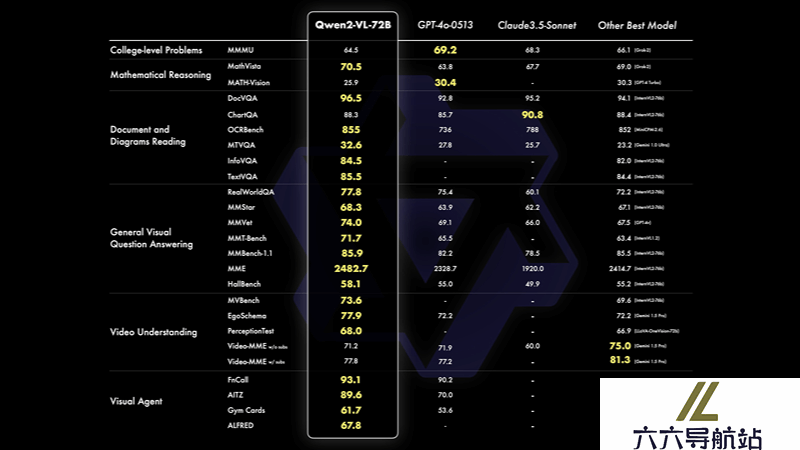
Qwen2-VL的项目地址
项目官网:https://qwenlm.github.io/zh/blog/qwen2-vl/GitHub仓库:https://github.com/QwenLM/Qwen2-VLHuggingFace模型库:https://huggingface.co/collections/Qwen/qwen2-vl魔搭社区:https://modelscope.cn/organization/qwen?tab=model体验Demo:https://huggingface.co/spaces/Qwen/Qwen2-VLQwen2-VL的应用场景
内容创作:Qwen2-VL能自动生成视频和图像内容的描述,助力创作者快速产出多媒体作品。教育辅助:作为教育工具,Qwen2-VL帮助学生解析数学问题和逻辑图表,提供解题指导。多语言翻译与理解:Qwen2-VL识别和翻译多语言文本,促进跨语言交流和内容理解。智能客服:集成实时聊天功能,Qwen2-VL提供即时的客户咨询服务。图像和视频分析:在安全监控和社交媒体管理中,Qwen2-VL分析视觉内容,识别关键信息。辅助设计:设计师用Qwen2-VL的图像理解能力获取设计灵感和概念图。自动化测试:Qwen2-VL在软件开发中自动检测界面和功能问题。数据检索与信息管理:Qwen2-VL通过视觉代理能力,提高信息检索和管理的自动化水平。辅助驾驶和机器人导航:Qwen2-VL作为视觉感知组件,辅助自动驾驶和机器人理解环境。医疗影像分析:Qwen2-VL辅助医疗专业人员分析医学影像,提升诊断效率。- 猜你喜欢
-
 Nonoisy提示指令
Nonoisy提示指令 -
 Listener.fm提示指令
Listener.fm提示指令 -
 Castmagic提示指令
Castmagic提示指令 -
 Metavoice Studio提示指令
Metavoice Studio提示指令 -
 Databass提示指令
Databass提示指令 -
 Ai|coustics提示指令
Ai|coustics提示指令 -
 Krisp提示指令
Krisp提示指令 -
 Noise Eraser提示指令
Noise Eraser提示指令 -
 TTSLabs提示指令
TTSLabs提示指令








- 相关AI应用
-
 Ezdubs.ai提示指令
Ezdubs.ai提示指令 -
 Adobe Podcast提示指令
Adobe Podcast提示指令 -
 Podcastle提示指令
Podcastle提示指令 -
 Koe Recast提示指令
Koe Recast提示指令 -
 Audio Strip提示指令
Audio Strip提示指令 -
 Audyo提示指令
Audyo提示指令 -
 MusicLM提示指令
MusicLM提示指令 -

-
 Drumloop AI提示指令
Drumloop AI提示指令









- 推荐AI教程资讯
- Qwen2-VL – 阿里巴巴达摩院开源的视觉多模态AI模型
- auto-video-generator – AI自动解说视频生成器
- HMoE – 腾讯混元团队提出的新型神经网络架构
- VFusion3D – Meta联合牛津大学推出的AI生成3D模型项目
- edge-tts – 开源的AI文字转语音项目
- LM Studio – 开源、傻瓜、一站式部署本地大模型 (LLM) 的应用平台
- Video-LLaVA2 – ChatLaw推出的开源多模态智能理解系统
- MUMU – 文本和图像驱动的多模态生成模型
- LLaVA-OneVision – 字节跳动推出的开源多模态AI模型
- CustomCrafter – 腾讯联合浙大推出的自定义视频生成框架
- 精选推荐
-
Drumloop AI2025-02-14提示指令
-
 2AI2025-02-12法律助手
2AI2025-02-12法律助手 -
 海瑞智法2025-01-02法律助手
海瑞智法2025-01-02法律助手 -
 BraveGPT2025-02-05提示指令
BraveGPT2025-02-05提示指令 -
 GrammarGPT2025-02-02法律助手
GrammarGPT2025-02-02法律助手 -
 Voiceful.io2025-02-13提示指令
Voiceful.io2025-02-13提示指令





- 推荐阅读阅读排行
-
-





- 推荐工具精选应用
-
-
Drumloop AI
评分:4
-
 ChatMindAI
ChatMindAI评分:4
-
 PromptStacks
PromptStacks评分:4
-
 Embra
Embra评分:4
-
 Entar.io
Entar.io评分:4
-



