SadTalker – 开源AI数字人项目,一键让照片说话
2025-02-21 14:54:38 小编:六六导航站
SadTalker是什么
SadTalker是西安交通大学、腾讯AI实验室和蚂蚁集团联合推出的开源AI数字人项目。SadTalker专注于通过单张人脸图像和语音音频,利用3D运动系数生成逼真的说话人脸动画。通过ExpNet精确学习面部表情,以及PoseVAE合成不同风格的头部运动,SadTalker能够创造出高质量、风格化的视频动画。SadTalker还包括了丰富的视频演示和消融研究,展示了其在多种语言和数据集上的应用效果。

SadTalker的主要功能
3D运动系数生成:从音频中提取头部姿态和表情的3D运动系数。ExpNet:一个专门设计的网络,用于从音频中学习准确的面部表情。PoseVAE:一个条件变分自编码器,用于不同风格的头部运动合成。3D面部渲染:将3D运动系数映射到3D关键点空间,用于渲染风格化的面部动画。多语言支持:能够处理不同语言的音频输入,生成相应语言的说话动画。SadTalker的技术原理
3D运动系数学习:SadTalker通过分析音频信号来学习3D运动系数,包括头部姿态和面部表情。是3D形态模型(3DMM)的关键参数。ExpNet(表情网络):用于从音频中提取面部表情信息。ExpNet通过学习音频与面部表情之间的映射关系,能够生成准确的面部表情动画。PoseVAE(头部姿态变分自编码器):PoseVAE是一个条件变分自编码器(Conditional Variational Autoencoder, CVAE),用于生成不同风格的头部运动。可以根据音频信号合成自然且风格化的头部姿态。3D面部渲染:SadTalker使用一种新颖的3D面部渲染技术,将学习到的3D运动系数映射到3D关键点空间。这个过程涉及到面部的几何和纹理信息,以生成逼真的面部动画。多模态学习:SadTalker在训练过程中同时考虑了音频和视觉信息,通过多模态学习来提高动画的自然度和准确性。风格化处理:SadTalker能够根据需要生成不同风格的人脸动画,涉及到对面部特征和运动的非线性变换,以适应不同的视觉风格。无监督学习:SadTalker在生成3D关键点时采用了无监督学习方法,意味着不需要大量的标注数据就能学习到有效的运动模式。数据融合:通过融合音频和视觉数据,SadTalker能生成与音频同步且表情自然的说话人脸动画。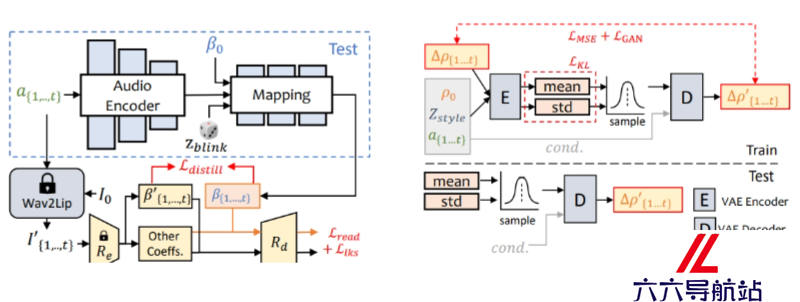
SadTalker的项目地址
GitHub仓库:https://sadtalker.github.io/- 猜你喜欢
-
 Aflorithmic提示指令
Aflorithmic提示指令 -
 RadioNewsAI提示指令
RadioNewsAI提示指令 -

-
 Respeecher提示指令
Respeecher提示指令 -
 Supertone提示指令
Supertone提示指令 -

-
 Voice Swap提示指令
Voice Swap提示指令 -
 Chord Variations提示指令
Chord Variations提示指令 -
 Gladia提示指令
Gladia提示指令









- 相关AI应用
-
 CrystalSound提示指令
CrystalSound提示指令 -
 RipX提示指令
RipX提示指令 -
 Audo Studio提示指令
Audo Studio提示指令 -
 PodPilot提示指令
PodPilot提示指令 -
 DeepZen提示指令
DeepZen提示指令 -
 Samplab提示指令
Samplab提示指令 -
 Dubb提示指令
Dubb提示指令 -
 Forever Voices提示指令
Forever Voices提示指令 -
 FolkTalk提示指令
FolkTalk提示指令








- 推荐AI教程资讯
- SadTalker – 开源AI数字人项目,一键让照片说话
- xGen-MM – Salesforce推出的开源多模态AI模型
- Phi-3.5 – 微软推出的新一代AI模型,mini、MoE混合和视觉模型
- Seed-ASR – 字节跳动推出的AI语音识别模型
- Moffee – 开源的Markdown转PPT工具
- 浦语灵笔 – 开源的多模态大模型,性能媲美GPT-4V
- 新壹视频大模型 – 新壹科技推出的AI视频创作大模型
- 书生·浦语 – 上海人工智能实验室推出的开源AI大模型
- MetaHuman-Stream – 实时交互流式AI数字人技术
- Half_illustration – 基于Flux.1 的LoRA模型,让照片秒变艺术大片
- 精选推荐
-
 Drumloop AI2025-02-14提示指令
Drumloop AI2025-02-14提示指令 -
 Gerwin2025-02-12法律助手
Gerwin2025-02-12法律助手 -
 法智2025-01-02法律助手
法智2025-01-02法律助手 -
 HealthGPT2025-02-11提示指令
HealthGPT2025-02-11提示指令 -
 AI Prompt Generator2025-01-02提示指令
AI Prompt Generator2025-01-02提示指令 -
 unbounce2025-02-02法律助手
unbounce2025-02-02法律助手






- 推荐阅读阅读排行
-
-





- 推荐工具精选应用
-
-
Drumloop AI
评分:4
-
 GPT智库 /互联网境外访问绿色通道
GPT智库 /互联网境外访问绿色通道评分:4
-
 Ogen AI
Ogen AI评分:4
-
 PromptPerfect
PromptPerfect评分:4
-
 Lalal.ai
Lalal.ai评分:4
-



