MOFA-Video – 腾讯开源的可控性AI图生视频模型
2025-02-27 13:46:44 小编:六六导航站
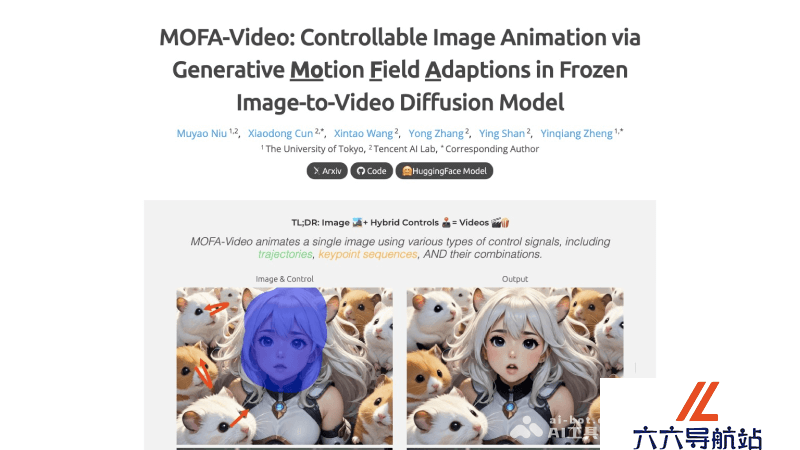
MOFA-Video是什么
MOFA-Video是由腾讯AI实验室和东京大学的研究人员开源的一个可控性的图像生成视频的模型,该技术利用生成运动场适应器对图像进行动画处理以生成视频。MOFA-Video能够在预训练的Stable Video Diffusion模型基础上,通过稀疏控制信号如手动轨迹、面部标记序列或音频等,实现对视频生成过程中动作的精细控制。MOFA-Video不仅能够单独使用这些控制信号,还能将它们组合使用,以零样本(zero-shot)的方式进行更复杂的动画制作,提供了一种全新的、高度可控的图像动画视频解决方案。
MOFA-Video的功能特色
轨迹控制动画:用户通过在图像上手动绘制轨迹,指导MOFA-Video生成相应的视频动画。这种功能特别适合需要精确控制物体或相机运动的场景。面部关键点动画:系统利用面部关键点数据,如通过面部识别技术获得的标记,来生成逼真的面部表情和头部动作动画。混合控制动画:MOFA-Video能够将轨迹控制和面部关键点控制相结合,实现面部表情和身体动作的同步动画,创造出复杂的多部分动画效果。音频驱动面部动画:通过分析音频信号,MOFA-Video能够生成与语音或音乐同步的面部动画,例如口型同步。视频驱动面部动画:使用参考视频,MOFA-Video能够使静态图像中的面部动作模仿视频中的动作,实现动态的面部表情再现。零样本多模态控制:MOFA-Video支持零样本学习,即不同控制信号可以无需额外训练即可组合使用,这大大提高了动画生成的灵活性和多样性。长视频生成能力:通过采用周期性采样策略,MOFA-Video能够生成比传统模型更长的视频动画,突破了帧数限制。用户界面操作:MOFA-Video提供了基于Gradio的简单易用的用户界面,用户可以通过这个界面直观地进行动画生成,无需具备专业的编程技能。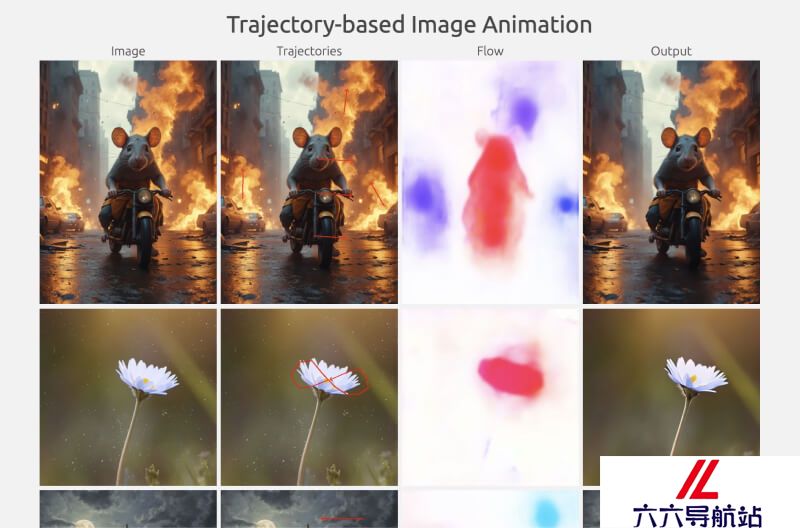
MOFA-Video的官网入口
官方项目主页:https://myniuuu.github.io/MOFA_VideoGitHub代码库:https://github.com/MyNiuuu/MOFA-Video基于轨迹的图像动画Gradio演示和模型检查点:https://huggingface.co/MyNiuuu/MOFA-Video-TrajGradio演示和混合控制图像动画检查点:https://huggingface.co/MyNiuuu/MOFA-Video-HybridMOFA-Video的工作原理
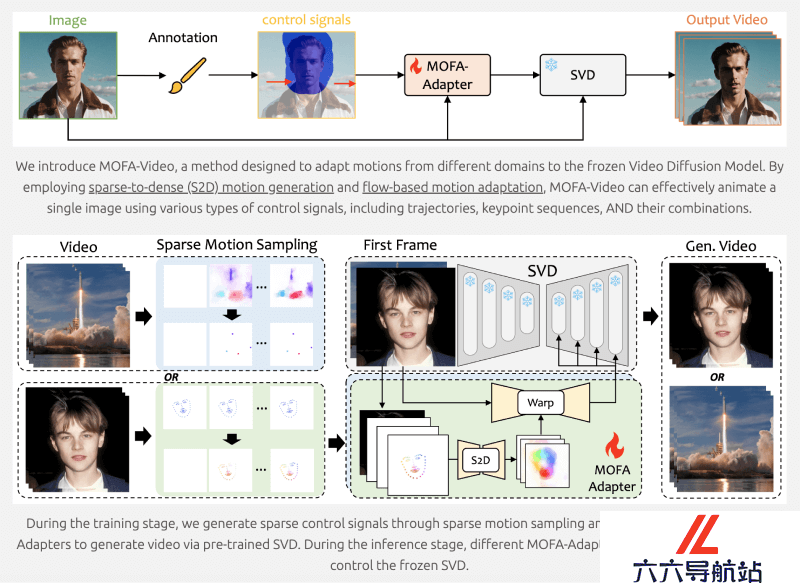 稀疏控制信号生成:在训练阶段,系统通过稀疏运动采样技术生成稀疏控制信号。这些信号可能是基于轨迹的动画控制点,面部关键点序列,或者是其他形式的运动指示。MOFA-Adapter设计:MOFA-Adapter是系统的核心,它是一个专门设计的网络结构,用于将稀疏控制信号转换为密集的运动场。这一组件包括:S2D网络:将稀疏的运动提示转换为密集的运动场。参考图像编码器:提取参考图像的多尺度特征,用于后续的运动场生成。特征融合编码器:将S2D网络生成的运动场与参考图像编码器的特征结合。多尺度特征提取:参考图像编码器对输入的参考图像进行处理,提取出多尺度的特征表示,这些特征将用于后续的视频帧生成过程中的引导和变形。运动场的生成与应用:S2D网络根据稀疏控制信号生成密集的运动场,这些运动场随后用于对多尺度特征进行空间变形,以模拟视频中的运动效果。预训练的SVD模型:MOFA-Adapter与预训练的Stable Video Diffusion模型(SVD)结合,利用从MOFA-Adapter获得的条件特征来引导视频帧的生成。空间变形:利用生成的运动场,系统对参考图像的多尺度特征进行空间变形,确保视频帧中的物体和场景元素按照预定的运动轨迹进行移动。视频帧生成:在特征空间中经过变形的特征被用于生成视频帧。这一过程涉及到从潜在空间中采样并逐步去除噪声,以重建清晰的视频帧。多模态控制信号集成:MOFA-Video能够处理来自不同源的控制信号,并将它们融合到统一的生成过程中,实现复杂的动画效果。零样本学习:MOFA-Adapter训练完成后,可以在不同控制域中无需额外训练即可联合工作,实现对视频生成的精细控制。长视频生成策略:为了生成更长的视频,MOFA-Video采用了周期性采样策略,通过在潜在空间中对帧进行分组和重叠采样,解决了长视频生成中的连贯性和计算复杂性问题。
稀疏控制信号生成:在训练阶段,系统通过稀疏运动采样技术生成稀疏控制信号。这些信号可能是基于轨迹的动画控制点,面部关键点序列,或者是其他形式的运动指示。MOFA-Adapter设计:MOFA-Adapter是系统的核心,它是一个专门设计的网络结构,用于将稀疏控制信号转换为密集的运动场。这一组件包括:S2D网络:将稀疏的运动提示转换为密集的运动场。参考图像编码器:提取参考图像的多尺度特征,用于后续的运动场生成。特征融合编码器:将S2D网络生成的运动场与参考图像编码器的特征结合。多尺度特征提取:参考图像编码器对输入的参考图像进行处理,提取出多尺度的特征表示,这些特征将用于后续的视频帧生成过程中的引导和变形。运动场的生成与应用:S2D网络根据稀疏控制信号生成密集的运动场,这些运动场随后用于对多尺度特征进行空间变形,以模拟视频中的运动效果。预训练的SVD模型:MOFA-Adapter与预训练的Stable Video Diffusion模型(SVD)结合,利用从MOFA-Adapter获得的条件特征来引导视频帧的生成。空间变形:利用生成的运动场,系统对参考图像的多尺度特征进行空间变形,确保视频帧中的物体和场景元素按照预定的运动轨迹进行移动。视频帧生成:在特征空间中经过变形的特征被用于生成视频帧。这一过程涉及到从潜在空间中采样并逐步去除噪声,以重建清晰的视频帧。多模态控制信号集成:MOFA-Video能够处理来自不同源的控制信号,并将它们融合到统一的生成过程中,实现复杂的动画效果。零样本学习:MOFA-Adapter训练完成后,可以在不同控制域中无需额外训练即可联合工作,实现对视频生成的精细控制。长视频生成策略:为了生成更长的视频,MOFA-Video采用了周期性采样策略,通过在潜在空间中对帧进行分组和重叠采样,解决了长视频生成中的连贯性和计算复杂性问题。 - 猜你喜欢
-
 Cyanite.ai提示指令
Cyanite.ai提示指令 -
 Piano Genie提示指令
Piano Genie提示指令 -
 Synthesizer V提示指令
Synthesizer V提示指令 -
 Cosonify提示指令
Cosonify提示指令 -
 Musico提示指令
Musico提示指令 -
 Loudly提示指令
Loudly提示指令 -
 Beatopia提示指令
Beatopia提示指令 -
 Trending sounds提示指令
Trending sounds提示指令 -
 Staccato提示指令
Staccato提示指令









- 相关AI应用
-
 RIFFIT Reader提示指令
RIFFIT Reader提示指令 -
 Brain.fm提示指令
Brain.fm提示指令 -
 A.V. Mapping提示指令
A.V. Mapping提示指令 -
 Audioshake提示指令
Audioshake提示指令 -
 Open Voice OS提示指令
Open Voice OS提示指令 -
 Chat Jams提示指令
Chat Jams提示指令 -
 Endel提示指令
Endel提示指令 -
 Lemonaid Music提示指令
Lemonaid Music提示指令 -
 Musicfy提示指令
Musicfy提示指令








- 推荐AI教程资讯
- MOFA-Video – 腾讯开源的可控性AI图生视频模型
- Gemma 2 – 谷歌DeepMind推出的新一代开源人工智能模型
- FreeAskInternet – 免费开源的本地AI搜索引擎
- Fish Speech – 开源的高效文本到语音合成TTS工具
- Moshi – 法国AI实验室Kyutai开发的实时音频多模态模型
- EchoMimic – 阿里推出的开源数字人项目,赋予静态图像以生动语音和表情
- MimicMotion – 腾讯推出的AI人像动态视频生成框架
- FunAudioLLM – 阿里巴巴通义团队推出的开源语音大模型
- Chameleon – Meta推出的图文混合多模态开源模型
- Mem0 – 一款开源的大语言模型记忆增强工具
- 精选推荐
-
 Drumloop AI2025-02-14提示指令
Drumloop AI2025-02-14提示指令 -
 讯飞听见写作2025-02-03法律助手
讯飞听见写作2025-02-03法律助手 -
 Superpower ChatGPT2025-02-01提示指令
Superpower ChatGPT2025-02-01提示指令 -
 IMI Prompt2025-02-06提示指令
IMI Prompt2025-02-06提示指令 -
 Ghostwrite2025-02-05提示指令
Ghostwrite2025-02-05提示指令 -
 Daydrm.ai2025-02-11法律助手
Daydrm.ai2025-02-11法律助手






- 推荐阅读阅读排行
-
-







- 推荐工具精选应用
-
-
Drumloop AI
评分:4
-
 DapperGPT
DapperGPT评分:4
-
Superpower ChatGPT
评分:4
-
 BraveGPT
BraveGPT评分:4
-
IMI Prompt
评分:4
-




