SepLLM – 基于分隔符压缩加速大语言模型的高效框架
2025-03-11 15:23:48 小编:六六导航站
SepLLM是什么
SepLLM是香港大学、华为诺亚方舟实验室等机构联合提出的用于加速大语言模型(LLM)的高效框架,通过压缩段落信息并消除冗余标记,显著提高了模型的推理速度和计算效率。SepLLM的核心是利用分隔符(如标点符号)对注意力机制的贡献,将段落信息压缩到这些标记中,减少计算负担。SepLLM在处理长序列(如400万标记)时表现出色,保持了低困惑度和高效率。支持多节点分布式训练,集成了多种加速操作(如fused rope和fused layer norm)。
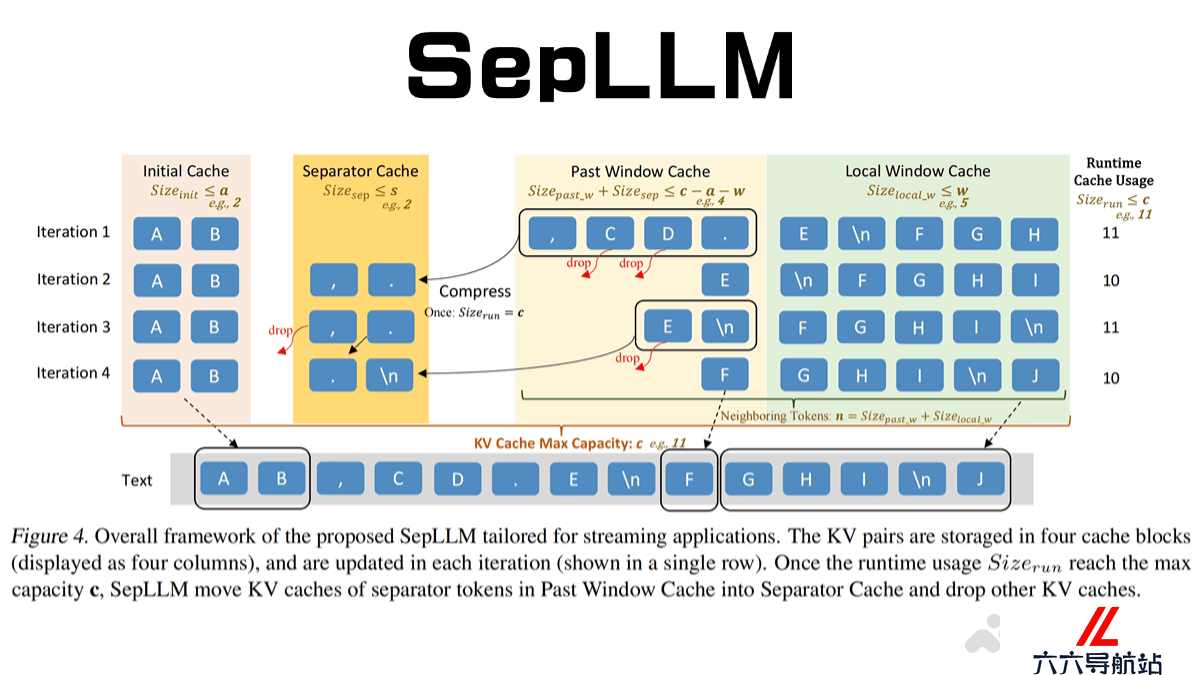
SepLLM的主要功能
长文本处理能力:SepLLM能高效处理超过400万个标记的长序列,适用于文档摘要、长对话等需要维持上下文连贯性的任务。推理与内存效率提升:在GSM8K-CoT基准测试中,SepLLM将KV缓存使用量减少了50%以上,同时计算成本降低28%,训练时间缩短26%,推理速度显著提升。多场景部署灵活性:SepLLM支持从零训练、微调和流式应用等多种部署场景,能与预训练模型无缝集成。支持多节点分布式训练:SepLLM的代码库支持高效的多节点分布式训练,集成了多种加速训练的操作(如fused rope、fused layer norm等)。SepLLM的技术原理
稀疏注意力机制:SepLLM主要关注三类标记:在自注意力层中,SepLLM通过mask矩阵限制注意力计算范围,仅计算上述三类标记之间的注意力,实现稀疏化。初始标记(Initial Tokens):序列开始的若干标记,作为注意力的锚点。邻近标记(Neighboring Tokens):当前标记附近的标记,用于保持局部语义连贯性。分隔符标记(Separator Tokens):如逗号、句号等,用于压缩存储段落信息。动态KV缓存管理:SepLLM设计了专门的缓存块,包括初始缓存、分隔符缓存、历史窗口缓存和局部窗口缓存。通过周期性压缩和更新策略,SepLLM能高效处理长序列,同时减少KV缓存的使用。SepLLM的项目地址
项目官网:https://sepllm.github.io/Github仓库:https://github.com/HKUDS/SepLLMarXiv技术论文:https://arxiv.org/pdf/2412.12094SepLLM的应用场景
流式应用:用于多轮对话、实时文本生成等流式场景,支持无限长度输入,保持高效的语言建模能力。推理与内存优化:通过减少KV缓存和计算成本,适用于资源受限的环境(如边缘计算、移动设备),降低部署成本。工业应用:在大规模商业应用中,降低部署成本,提升服务效率,支持高并发请求。研究与创新:为注意力机制优化提供新思路,支持多语言、特定领域优化和硬件适配等研究方向。- 猜你喜欢
-
 MusicTGA-HR提示指令
MusicTGA-HR提示指令 -
 RappingAI提示指令
RappingAI提示指令 -
 Boomy提示指令
Boomy提示指令 -
 TwoShot提示指令
TwoShot提示指令 -
 Weet提示指令
Weet提示指令 -
 Muzaic Studio提示指令
Muzaic Studio提示指令 -

-
 HookGen提示指令
HookGen提示指令 -
 DadaBots提示指令
DadaBots提示指令









- 相关AI应用
-
 Playlistable提示指令
Playlistable提示指令 -
 Riffusion提示指令
Riffusion提示指令 -
 WZRD提示指令
WZRD提示指令 -

-
 Cyanite.ai提示指令
Cyanite.ai提示指令 -
 Piano Genie提示指令
Piano Genie提示指令 -
 Synthesizer V提示指令
Synthesizer V提示指令 -
 Cosonify提示指令
Cosonify提示指令 -
 Musico提示指令
Musico提示指令









- 推荐AI教程资讯
- SepLLM – 基于分隔符压缩加速大语言模型的高效框架
- CogView4 – 智谱开源的AI文生图模型,支持生成汉字
- PRefLexOR – MIT 团队推出的新型自学习AI框架
- Probly – AI电子表格工具,交互式生成分析结果或可视化图表
- MindLLM – 耶鲁联合剑桥等机构推出的医疗领域 AI 模型
- MiniMind – 开源的AI模型训练工具,2小时训练25.8M小模型
- Fractal Generative Models – 麻省理工推出的分形生成模型
- SpeciesNet – Google 开源的动物物种识别 AI 模型
- Image-01 – MiniMax 推出的文本到图像生成模型
- SuperGPQA – 豆包大模型联合 M-A-P 开源的知识推理基准测试集
- 精选推荐
-
 WiziShop2025-02-02法律助手
WiziShop2025-02-02法律助手 -
 Endel2025-02-25提示指令
Endel2025-02-25提示指令 -
 Voice.ai2025-02-14提示指令
Voice.ai2025-02-14提示指令 -
 Awesome ChatGPT Prompts2025-01-02提示指令
Awesome ChatGPT Prompts2025-01-02提示指令 -
 Co-Writer AI2025-02-12法律助手
Co-Writer AI2025-02-12法律助手 -
 ChatLaw2024-12-31法律助手
ChatLaw2024-12-31法律助手






- 推荐阅读阅读排行
-
-

-
-

-
-
 AutoRAG – 中科院开源的自主迭代检索模型AI教程资讯
AutoRAG – 中科院开源的自主迭代检索模型AI教程资讯
-








- 推荐工具精选应用
-
-
 Vanityai
Vanityai评分:4
-
 ChatGPT Prompt Plus
ChatGPT Prompt Plus评分:4
-

-
 Chat Jams
Chat Jams评分:4
-
 SpeechGen
SpeechGen评分:4
-




