WebLI-100B – 谷歌 DeepMind 推出的1000亿视觉语言数据集
2025-03-19 14:16:23 小编:六六导航站
WebLI-100B是什么
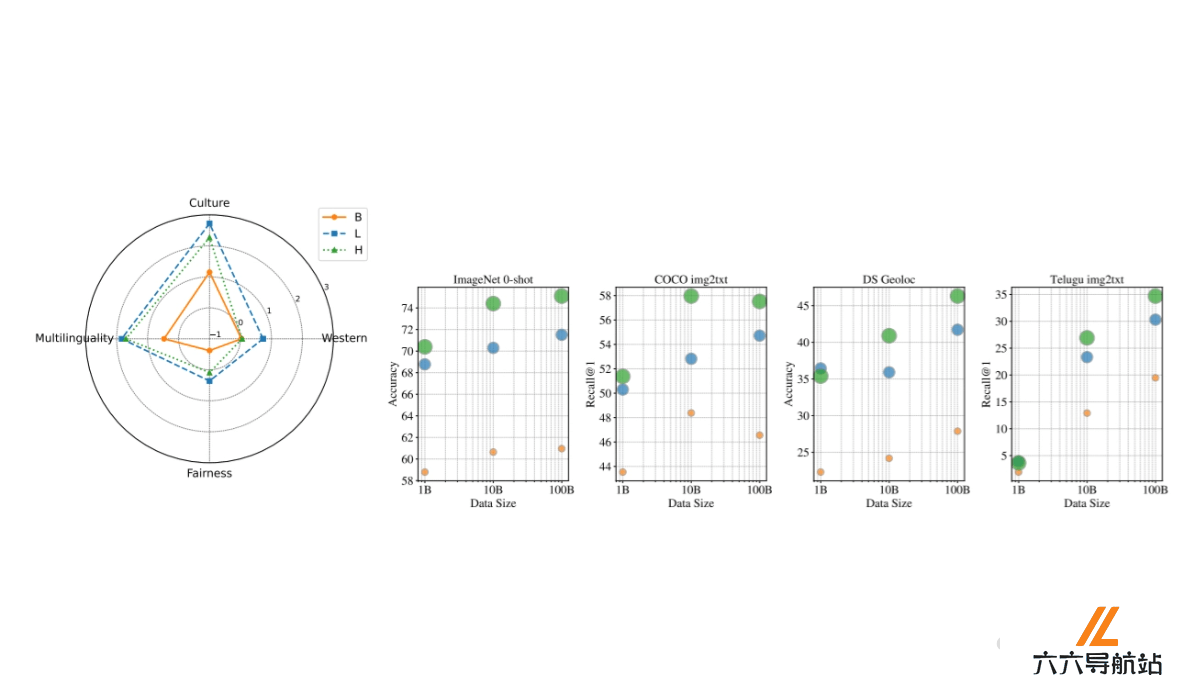
WebLI-100B是Google DeepMind推出的包含1000亿图像-文本对的超大规模数据集,用在预训练视觉语言模型(VLMs)。WebLI-100B是WebLI数据集的扩展版本,基于从网络中收集大量图像及其对应的标题或页面标题作为文本配对信息构建而成。WebLI-100B的规模是之前最大视觉语言数据集的十倍,用海量数据提升模型对长尾概念、文化多样性和多语言内容的理解能力。研究者在构建时仅进行基本的数据过滤,保留尽可能多的语言和文化多样性。WebLI-100B的出现为训练更具包容性的多模态模型提供了重要的基础资源。
WebLI-100B的主要功能
支持大规模预训练:WebLI-100B提供1000亿个图像-文本对,为VLMs的预训练提供丰富的数据资源,显著提升模型在多种任务上的性能。提升文化多样性:包含来自不同文化背景的图像和文本,帮助模型更好地理解和生成与不同文化相关的视觉和语言内容。增强多语言能力:数据集中包含多种语言的文本,有助于提升模型在低资源语言上的性能,促进多语言任务的开发和应用。支持多模态任务:WebLI-100B的数据用在多种多模态任务,如图像分类、图像描述生成、视觉问答等,为多模态模型的开发提供强大的支持。WebLI-100B的技术原理
数据收集:来源:WebLI-100B的数据主要来源于互联网,通过大规模的网络爬取收集图像及其对应的文本描述(如图像的alt文本或页面标题)。规模:数据集包含1000亿个图像-文本对,是迄今为止最大的视觉语言数据集之一。数据过滤:基本过滤:为了确保数据的质量和多样性,WebLI-100B仅进行了基本的数据过滤,例如移除有害图像和个人身份信息(PII),以保留尽可能多的语言和文化多样性。质量过滤(可选):研究中还探讨了使用CLIP等模型进行数据过滤,以提高数据质量,但这种过滤可能会减少某些文化背景的代表性。数据处理:文本处理:将图像的alt文本和页面标题作为配对文本,使用多语言mt5分词器进行分词处理,确保文本数据的多样性和一致性。图像处理:将图像调整为224×224像素的分辨率,适应模型的输入要求。WebLI-100B的项目地址
arXiv技术论文:https://arxiv.org/pdf/2502.07617WebLI-100B的应用场景
人工智能研究者:用在模型预训练,探索新算法,提升视觉语言模型性能。工程师:开发多语言和跨文化的应用,如图像描述、视觉问答和内容推荐系统。内容创作者:生成多语言的图像描述和标签,提升内容的本地化和多样性。跨文化研究者:分析不同文化背景下的图像和文本,研究文化差异。教育工作者和学生:作为教学资源,学习多模态数据处理和分析。- 猜你喜欢
-
 MusicTGA-HR提示指令
MusicTGA-HR提示指令 -
 RappingAI提示指令
RappingAI提示指令 -
 Boomy提示指令
Boomy提示指令 -
 TwoShot提示指令
TwoShot提示指令 -
 Weet提示指令
Weet提示指令 -
 Muzaic Studio提示指令
Muzaic Studio提示指令 -

-
 HookGen提示指令
HookGen提示指令 -
 DadaBots提示指令
DadaBots提示指令









- 相关AI应用
-
 Playlistable提示指令
Playlistable提示指令 -
 Riffusion提示指令
Riffusion提示指令 -
 WZRD提示指令
WZRD提示指令 -

-
 Cyanite.ai提示指令
Cyanite.ai提示指令 -
 Piano Genie提示指令
Piano Genie提示指令 -
 Synthesizer V提示指令
Synthesizer V提示指令 -
 Cosonify提示指令
Cosonify提示指令 -
 Musico提示指令
Musico提示指令









- 推荐AI教程资讯
- WebLI-100B – 谷歌 DeepMind 推出的1000亿视觉语言数据集
- ChatGPT Canvas免费啦!集成Python仿真器,支持在线修Bug,生产力飙升
- BAG – 港中文联合腾讯推出的3D可穿戴资产生成技术
- 通古大模型 – 华南理工大学推出的古籍大语言模型
- ENEL – 上海 AI Lab 推出的无编码器3D大型多模态模型
- AnyCharV – 港中文联合清华等机构推出的角色可控视频生成框架
- NobodyWho – AI游戏引擎插件,本地运行 LLM 实现互动小说创作
- PIKE-RAG – 微软亚洲研究院推出的检索增强型生成框架
- Collaborative Gym – 支持人与AI代理实时交互协作的评估框架
- TIGER – 清华大学推出的轻量级语音分离模型
- 精选推荐
-
 元典智库2024-12-31法律助手
元典智库2024-12-31法律助手 -
Piano Genie2025-02-27提示指令
-
 Ezdubs.ai2025-02-18提示指令
Ezdubs.ai2025-02-18提示指令 -
 文心一言2025-01-29提示指令
文心一言2025-01-29提示指令 -
 Superflow Rewrite2025-02-18法律助手
Superflow Rewrite2025-02-18法律助手 -
 WisdomAI by Searchie2025-01-29法律助手
WisdomAI by Searchie2025-01-29法律助手





- 推荐阅读阅读排行
-
-





- 推荐工具精选应用
-
-
 Voiceful.io
Voiceful.io评分:4
-

-
Piano Genie
评分:4
-
Ezdubs.ai
评分:4
-
文心一言
评分:4
-

