EmoLLM – 专注于心理健康支持的大语言模型
2025-03-26 16:58:17 小编:六六导航站
EmoLLM是什么
EmoLLM 是专注于心理健康支持的大型语言模型,通过多模态情感理解为用户提供情绪辅导和心理支持。结合了文本、图像、视频等多种数据形式,基于先进的多视角视觉投影技术,从不同角度捕捉情感线索,更全面地理解用户的情绪状态。EmoLLM 基于多种开源大语言模型进行指令微调,支持情绪识别、意图理解、幽默检测和仇恨检测等情感任务。
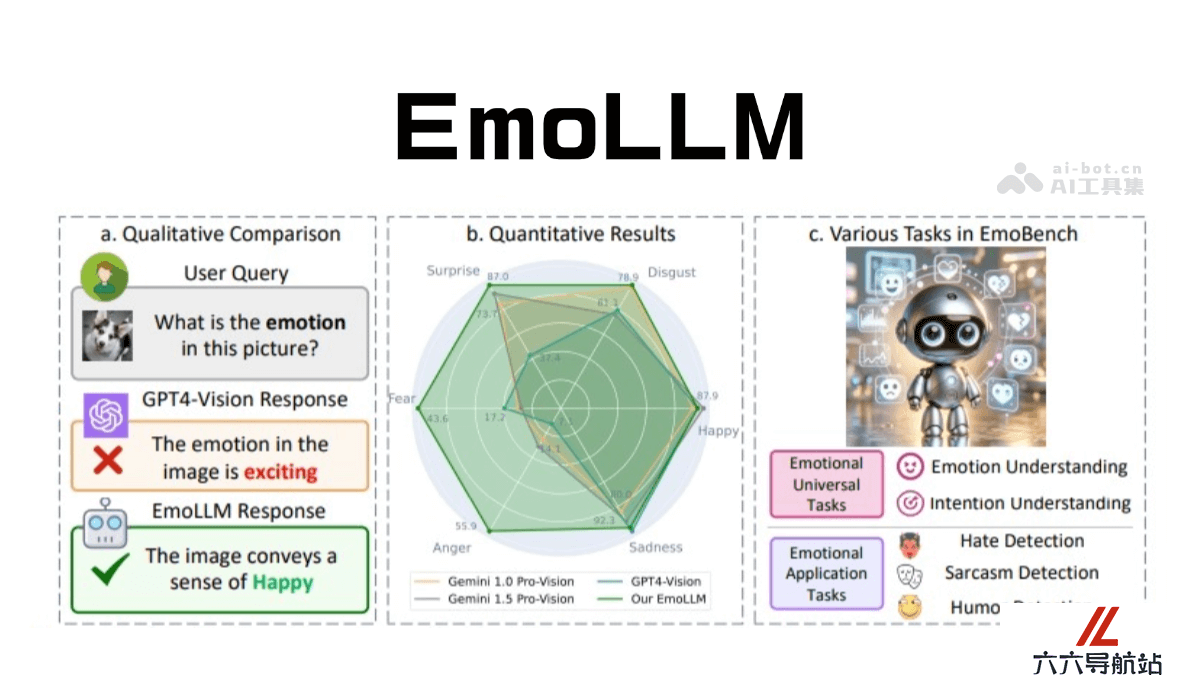
EmoLLM的主要功能
理解用户:通过对话交互,识别用户的情绪状态和心理需求。情感支持:提供情感支持,帮助用户缓解压力和焦虑。心理辅导:结合认知行为疗法等方法,引导用户改善情绪管理和应对策略。角色扮演:根据不同用户的需求,提供多种角色(如心理咨询师、温柔御姐、爹系男友等)的对话体验。个性化辅导:根据用户的反馈和进展,提供定制化的心理辅导方案。心理健康评估:使用科学工具评估用户的心理状态,诊断可能存在的心理问题。教育和预防:提供心理健康知识,帮助用户了解如何预防心理问题。多轮对话支持:通过多轮对话数据集,提供持续的心理辅导和支持。社会支持系统:考虑家庭、工作、社区和文化背景对心理健康的影响,提供社会支持系统的指导。EmoLLM的技术原理
多视角视觉投影(Multi-perspective Visual Projection):EmoLLM 通过多视角视觉投影技术,从多个角度捕捉视觉数据中的情感线索。分析单个视角下的情感信息,通过构建基于图的表示来捕捉对象特征之间的关系。通过联合挖掘内容信息和关系信息,模型能提取出更适合情感任务的特征。情感引导提示(EmoPrompt):EmoPrompt 是用于指导多模态大型语言模型(MLLMs)正确推理情感的技术。通过引入特定任务的示例,结合 GPT-4V 的能力生成准确的推理链(Chain-of-Thought, CoT),确保模型在情感理解上的准确性。多模态编码:EmoLLM 集成了多种模态编码器,以处理文本、图像和音频等多种输入。例如,使用 CLIP-VIT-L/14 模型处理视觉信息,WHISPER-BASE 模型处理音频信号,以及基于 LLaMA2-7B 的文本编码器处理文本数据。指令微调:EmoLLM 基于先进的指令微调技术,如 QLORA 和全量微调,对原始语言模型进行精细化调整,能更好地适应心理健康领域的复杂情感语境。EmoLLM的项目地址
GitHub仓库:https://github.com/yan9qu/EmoLLMarXiv技术论文:https://arxiv.org/pdf/2406.16442EmoLLM的应用场景
心理健康辅导:为用户提供情绪支持和建议。情感分析:用于社交媒体情感监测、心理健康监测等。多模态情感任务:如图像和视频中的情感识别。- 猜你喜欢
-
 MusicTGA-HR提示指令
MusicTGA-HR提示指令 -
 RappingAI提示指令
RappingAI提示指令 -
 Boomy提示指令
Boomy提示指令 -
 TwoShot提示指令
TwoShot提示指令 -
 Weet提示指令
Weet提示指令 -
 Muzaic Studio提示指令
Muzaic Studio提示指令 -

-
 HookGen提示指令
HookGen提示指令 -
 DadaBots提示指令
DadaBots提示指令









- 相关AI应用
-
 Playlistable提示指令
Playlistable提示指令 -
 Riffusion提示指令
Riffusion提示指令 -
 WZRD提示指令
WZRD提示指令 -

-
 Cyanite.ai提示指令
Cyanite.ai提示指令 -
 Piano Genie提示指令
Piano Genie提示指令 -
 Synthesizer V提示指令
Synthesizer V提示指令 -
 Cosonify提示指令
Cosonify提示指令 -
 Musico提示指令
Musico提示指令









- 推荐AI教程资讯
- EmoLLM – 专注于心理健康支持的大语言模型
- Step-Video V2 – 阶跃星辰推出的升级版视频生成模型
- 人类没有足够的高质量语料给AI学了,2026年就用尽
- UI-TARS – 字节跳动推出的开源原生 GUI 代理模型
- EMO2 – 阿里研究院推出的音频驱动头像视频生成技术
- PaSa – 字节跳动推出的学术论文检索智能体
- 首次引入视觉定位,实现细粒度多模态联合理解,已开源&demo可玩
- Baichuan-M1-preview – 百川智能推出的国内首个全场景深度思考模型
- TokenVerse – DeepMind等机构推出的多概念个性化图像生成方法
- Baichuan-M1-14B – 百川智能推出的行业首个开源医疗增强大模型





- 推荐阅读阅读排行
-
-





- 推荐工具精选应用
-
-
-
 Noise Eraser
Noise Eraser评分:4
-
 通义千问
通义千问评分:4
-
 Samplab
Samplab评分:4
-
 悟智写作
悟智写作评分:4
-



