AniPortrait – 腾讯开源的照片对口型视频生成框架
2025-05-07 15:07:45 小编:六六导航站
AniPortrait是什么
AniPortrait是腾讯开源的照片对口型AI视频生成框架,类似于此前阿里推出的EMO,能够通过音频和一张参考肖像图片生成高质量的动画。AniPortrait的工作原理分为两个阶段:首先从音频中提取3D面部特征,并将其转换为2D面部标记点;然后,利用扩散模型和运动模块,将这些标记点转换成连贯且逼真的动画。该框架的优势在于其生成的动画具有高度的自然性和多样性,同时提供了编辑和再现面部动作的灵活性。

AniPortrait的官网入口
GitHub代码库:https://github.com/Zejun-Yang/AniPortraitarXiv研究论文:https://arxiv.org/abs/2403.17694Hugging Face模型:https://huggingface.co/ZJYang/AniPortrait/tree/mainHugging Face Demo:https://huggingface.co/spaces/ZJYang/AniPortrait_officialAniPortrait的功能特性
音频驱动的动画生成:AniPortrait能够根据输入的音频文件自动生成与语音同步的面部动画,包括嘴唇的运动、面部表情和头部姿势。高质量的视觉效果:通过使用扩散模型和运动模块,AniPortrait能够产生高分辨率、视觉上逼真的肖像动画,提供出色的视觉体验。时间一致性:该框架确保动画在时间上的连贯性,使得动画中的角色动作流畅自然,没有突兀的跳跃或不一致。灵活性和可控性:利用3D面部表示作为中间特征,AniPortrait提供了对动画编辑的灵活性,允许用户对生成的动画进行进一步的定制和调整。面部表情和嘴唇动作的精确捕捉:通过改进的PoseGuider模块和多尺度策略,AniPortrait能够精确捕捉和再现嘴唇的微妙动作和复杂的面部表情。与参考图像的一致性:框架通过整合参考图像的外观信息,确保生成的动画在视觉上与原始肖像保持一致,避免了身份不匹配的问题。AniPortrait的工作机制
AniPortrait主要由两个模块组成:Audio2Lmk和Lmk2Video。
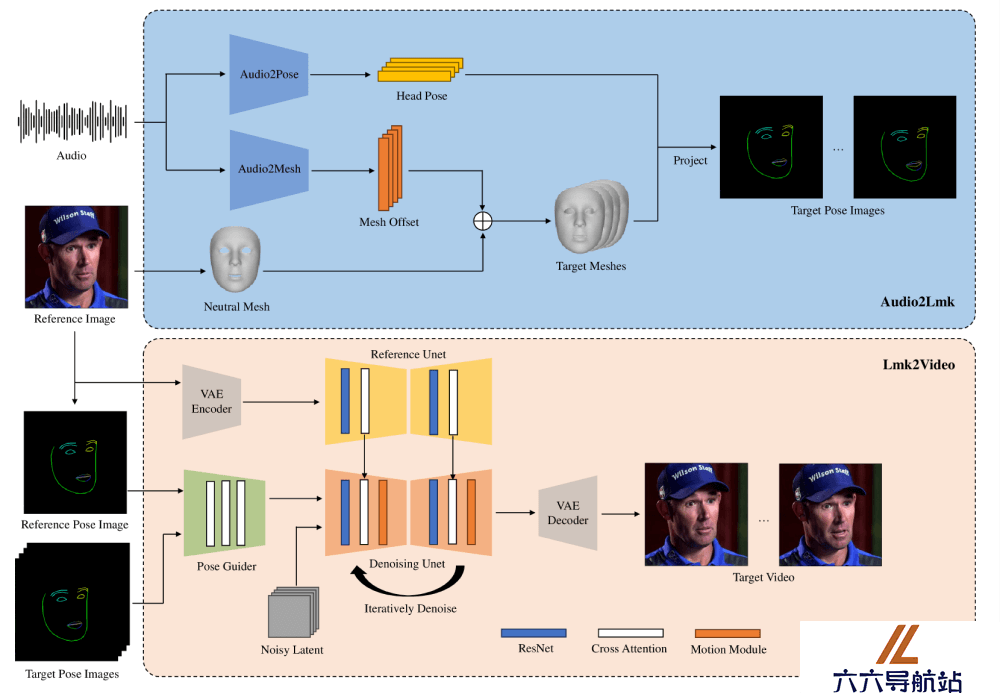
1. Audio2Lmk模块(音频到2D面部标记点)
Audio2Lmk模块的目标是从音频输入中提取一系列面部表情和嘴唇动作的3D面部网格和头部姿势信息。首先,使用预训练的wav2vec模型来提取音频特征,这个模型能够准确识别音频中的发音和语调,对于生成逼真的面部动画至关重要。然后,利用这些音频特征,通过两个全连接层转换成3D面部网格。对于头部姿势的预测,也使用wav2vec网络作为骨干,但不共享权重,因为姿势与音频中的节奏和语调更为相关。此外,使用变压器解码器来解码姿势序列,并通过交叉注意力机制将音频特征整合到解码器中。最终,通过透视投影将3D网格和姿势信息转换为2D面部标记点序列。
2. Lmk2Video模块(2D面部标记点到视频)
Lmk2Video模块负责根据参考肖像图像和一系列面部标记点生成时间上一致的高质量肖像视频,参考了AnimateAnyone的网络架构作为灵感来源,采用Stable Diffusion 1.5作为骨干,结合时间运动模块,将多帧噪声输入转换为一系列视频帧。此外,引入了一个与SD1.5结构相同的ReferenceNet,用于从参考图像中提取外观信息,并将其整合到骨干网络中,确保视频中的面部身份保持一致。为了提高对嘴唇动作的捕捉精度,增强了PoseGuider模块的设计,采用了ControlNet的多尺度策略,并将参考图像的标记点作为额外输入,通过交叉注意力模块促进参考标记点与每一帧目标标记点之间的交互,帮助网络更好地理解面部标记点与外观之间的关系。
- 猜你喜欢
-
 MusicTGA-HR提示指令
MusicTGA-HR提示指令 -
 RappingAI提示指令
RappingAI提示指令 -
 Boomy提示指令
Boomy提示指令 -
 TwoShot提示指令
TwoShot提示指令 -
 Weet提示指令
Weet提示指令 -
 Muzaic Studio提示指令
Muzaic Studio提示指令 -

-
 HookGen提示指令
HookGen提示指令 -
 DadaBots提示指令
DadaBots提示指令









- 相关AI应用
-
 Playlistable提示指令
Playlistable提示指令 -
 Riffusion提示指令
Riffusion提示指令 -
 WZRD提示指令
WZRD提示指令 -

-
 Cyanite.ai提示指令
Cyanite.ai提示指令 -
 Piano Genie提示指令
Piano Genie提示指令 -
 Synthesizer V提示指令
Synthesizer V提示指令 -
 Cosonify提示指令
Cosonify提示指令 -
 Musico提示指令
Musico提示指令









- 推荐AI教程资讯
- AniPortrait – 腾讯开源的照片对口型视频生成框架
- InstantStyle – 开源的个性化文本到图像生成框架,保留风格一致性
- DesignEdit – 微软等开源的AI图像分层处理编辑框架
- CodeGemma – 谷歌开源推出的代码生成大模型
- Parler-TTS – Hugging Face开源的文本转语音模型
- VASA-1 – 微软推出的静态照片对口型视频生成框架
- Llama 3 – Meta开源推出的新一代大语言模型
- FunClip – 阿里达摩院开源的AI自动视频剪辑工具
- Phi-3 – 微软最新推出的新一代小模型系列
- CogVLM2 – 智谱AI推出的新一代多模态大模型
- 精选推荐
-
 Koolio.ai2025-02-19提示指令
Koolio.ai2025-02-19提示指令 -
 Superpower ChatGPT2025-02-01提示指令
Superpower ChatGPT2025-02-01提示指令 -
 Learning Prompt2025-01-02提示指令
Learning Prompt2025-01-02提示指令 -
 ChatMindAI2025-01-27提示指令
ChatMindAI2025-01-27提示指令 -
 Epagestore.ai2025-02-05法律助手
Epagestore.ai2025-02-05法律助手 -
 Soundraw2025-02-24提示指令
Soundraw2025-02-24提示指令






- 推荐阅读阅读排行
-
-
-
-
-
 MDM – 苹果推出开源的新型扩散模型框架AI教程资讯
MDM – 苹果推出开源的新型扩散模型框架AI教程资讯 -

-





- 推荐工具精选应用
-
-
Koolio.ai
评分:4
-
Superpower ChatGPT
评分:4
-
Soundraw
评分:4
-
Learning Prompt
评分:4
-
ChatMindAI
评分:4
-